I've been using weechat to connect to IRC since late 2016 and one
of its killer feature is relays. They let use other frontends like the Weechat
Android app or the amazing Glowing Bear (packaged in
Debian Bullseye by yours truly).
Sadly, relays also used to be somewhat of a security risk: anyone with access to
a relay1 could run scripts on the machine running weechat by using
commands such as /exec or /script. Not great.
Since version 2.5 (Buster had version 2.3), you can mitigate this
risk by setting a command allowlist for relays. Later versions implemented a
sane default by blocking the following commands:
/exec
/fset
/set
/unset
/plugin
/script
/python
/perl
/ruby
/lua
/tcl
/guile
/javascript
/php
/secure
/upgrade
/quit
Sadly, this default didn't make in into Bullseye. If you are
running weechat and are using the relays feature, after upgrading to
Bullseye, I would recommend you run the following commands in the weechat
TUI:
I built my last desktop computer what seems like ages ago. In 2011, I was in a
very different place, both financially and as a person. At the time, I was
earning minimum wage at my school's caf to pay rent. Since the caf was owned
by the school cooperative, I had an employee discount on computer parts. This
gave me a chance to build my first computer from spare parts at a reasonable
price.
After 10 years of service1, the time has come to upgrade. Although this
machine was still more than capable for day to day tasks like browsing the web
or playing casual video games, it started to show its limits when time came to
do more serious work.
Old computer specs:
I first started considering an upgrade in September 2020: David Bremner was
kindly fixing a bug in ledger that kept me from balancing my books
and since it seemed like a class of bug that would've been easily caught by an
autopkgtest, I decided to add one.
After adding the necessary snippets to run the upstream testsuite (an easy task
I've done multiple times now), I ran sbuild and ... my computer froze and
crashed. Somehow, what I thought was a simple Python package was maxing all the
cores on my CPU and using all of the 8GB of memory I had available.2
A few month later, I worked on jruby and the builds took 20 to 30 minutes
long enough to completely disrupt my flow. The same thing happened when I
wanted to work on lintian: the testsuite would take more than 15 minutes to
run, making quick iterations impossible.
Sadly, the pandemic completely wrecked the computer hardware market and prices
here in Canada have only recently started to go down again. As a result, I had
to wait more time than I would've liked not to pay scalper prices.
New computer specs:
The difference between the two machines is pretty staggering: I've gone from a
CPU with 2 cores and 8 threads, to one with 12 cores and 24 threads. Not only
that, but single-threaded performance has also vastly increased in those 10
years.
A good example would be building grammalecte, a package I've recently
sponsored. I feel it's a good benchmark, since the build relies
on single-threaded performance for the normal Python operations, while being
threaded when it compiles the dictionaries.
On the old computer:
Build needed 00:10:07, 273040k disk space
And as you can see, on the new computer the build time has been significantly
reduced:
Build needed 00:03:18, 273040k disk space
Same goes for things like the lintian testsuite. Since it's a very
multi-threaded workload, it now takes less than 2 minutes to run; a 750%
improvement.
All this to say I'm happy with my purchase. And lo and behold I can now
build ledger without a hitch, even though it maxes my 24 threads and uses 28GB
of RAM. Who would've thought...
I managed to fry that PC's motherboard in 2016 and later replaced it with
a brand new one. I also upgraded the storage along the way, from a very cheap
cacheless 120GB SSD to a larger Samsung 850 EVO SATA drive.
As it turns out, ledger is mostly written in C++ :)
Last weekend Debian Quebec held a Bug Squashing Party to try to fix some
bugs in the upcoming Debian Bullseye.
I wasn't convinced at first, but Tassia's contagious energy and willingness to
help organise the event eventually won me over. And shockers! it was
really fun.
We fixed a couple of RC bugs, held lightning talks and had a
virtual pizza party!
My lightning talk on autopkgtests was well received and a few people decided to
migrate to sbuild and enable autopkgtests by default.
Sergio's talk on debuginfod was incredibly interesting. I'm not a C
programmer and the live demo made me understand how this service can help
making debugging C easier.
Jerome's talk on using Yubikeys to unlock LUKS encrypted drives was also very
good! It also served as a reminder that Yubico's product are much more
featureful and convenient to use than other Open Hardware/ Free Software
hardware tokens. Hopefully that will change as enterprises like Nitrokey and
Solokey mature.
This was my third BSP, crazy how time flies... With the Bullseye release closing
in, you should try to join or organise one!
While I'm overall very happy about my migration to an OpenPGP hardware
token, the process wasn't entirely seamless and I had to hack around
some issues, for example the PIN caching behavior in GnuPG.
As described in this bug the cache-ttl parameter in GnuPG is not
implemented and thus does nothing. This means once you type in your PIN, it is
cached for as long as the token is plugged.
Security-wise, this is not great. Instead of manually disconnecting the token
frequently, I've come up with a script that restarts scdameon if the token
hasn't been used during the last X minutes.
It seems to work well and I call it using this cron entry:
*/5 * * * * my_user /usr/local/bin/restart-scdaemon
To get a log from scdaemon, you'll need a ~/.gnupg/scdaemon.conf file that
looks like this:
debug-level basic
log-file /var/log/scdaemon.log
Hopefully it can be useful to others!
#!/usr/bin/python3
# Copyright 2021, Louis-Philippe V ronneau <pollo@debian.org>
#
# This script is free software: you can redistribute it and/or modify it under
# the terms of the GNU General Public License as published by the Free Software
# Foundation, either version 3 of the License, or (at your option) any later
# version.
#
# This script is distributed in the hope that it will be useful, but WITHOUT
# ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS
# FOR A PARTICULAR PURPOSE. See the GNU General Public License for more
# details.
#
# You should have received a copy of the GNU General Public License along with
# this script. If not, see <http://www.gnu.org/licenses/>.
"""
This script restarts scdaemon after X minutes of inactivity to reset the PIN
cache. It is meant to be ran by cron each X/2 minutes.
This is needed because there is currently no way to set a cache time for
smartcards. See https://dev.gnupg.org/T3362#137811 for more details.
"""
import os
import sys
import subprocess
from datetime import datetime, timedelta
from argparse import ArgumentParser
p = ArgumentParser(description=__doc__)
p.add_argument('-l', '--log', default="/var/log/scdaemon.log",
help='Path to the scdaemon log file.')
p.add_argument('-t', '--timeout', type=int, default="10",
help=("Desired cache time in minutes."))
args = p.parse_args()
def get_last_line(scdaemon_log):
"""Returns the last line of the scdameon log file."""
with open(scdaemon_log, 'rb') as f:
f.seek(-2, os.SEEK_END)
while f.read(1) != b'\n':
f.seek(-2, os.SEEK_CUR)
last_line = f.readline().decode()
return last_line
def check_time(last_line, timeout):
"""Returns True if scdaemon hasn't been called since the defined timeout."""
# We don't need to restart scdaemon if no gpg command has been run since
# the last time it was restarted.
should_restart = True
if "OK closing connection" in last_line:
should_restart = False
else:
last_time = datetime.strptime(last_line[:19], '%Y-%m-%d %H:%M:%S')
now = datetime.now()
delta = now - last_time
if delta <= timedelta(minutes = timeout):
should_restart = False
return should_restart
def restart_scdaemon(scdaemon_log):
"""Restart scdaemon and verify the restart process was successful."""
subprocess.run(['gpgconf', '--reload', 'scdaemon'], check=True)
last_line = get_last_line(scdaemon_log)
if "OK closing connection" not in last_line:
sys.exit("Restarting scdameon has failed.")
def main():
"""Main function."""
last_line = get_last_line(args.log)
should_restart = check_time(last_line, args.timeout)
if should_restart:
restart_scdaemon(args.log)
if __name__ == "__main__":
main()
-----BEGIN PGP SIGNED MESSAGE-----
Hash: SHA512
Sun, 07 Mar 2021 13:00:17 -0500
I've recently set up a new OpenPGP key and will be transitioning away from my
old one.
It is a chance for me to start using a OpenPGP hardware token and to transition
to a new personal email address (my main public contact is still my
@debian.org address).
Please note that I've partially redacted some email addresses from this
statement to minimise the amount of spam I receive. It shouldn't be hard for
actual humans to follow the instructions below to find the complete addresses.
The old key will continue to be valid for a few months, but will eventually be
revoked.
You might know my old OpenPGP certificate as:
pub rsa4096/0x7AEAC4EC6AAA0A97 2014-12-22 [expires: 2021-06-02]
Key fingerprint = 677F 54F1 FA86 81AD 8EC0 BCE6 7AEA C4EC 6AAA 0A97
uid Louis-Philippe V ronneau <REDACTED@riseup.net>
uid Louis-Philippe V ronneau (alias) <REDACTED@riseup.net>
uid Louis-Philippe V ronneau (debian) <REDACTED@debian.org>
My new OpenPGP certificate is:
pub ed25519/0xE1E5457C8BAD4113 2021-03-06 [expires: 2022-03-06]
Key fingerprint = F64D 61D3 21F3 CB48 9156 753D E1E5 457C 8BAD 4113
uid Louis-Philippe V ronneau <REDACTED@veronneau.org>
uid Louis-Philippe V ronneau <REDACTED@debian.org>
These days, I mostly use my key for Debian and to sign git commit. I don't
really expect you to sign my new key if you had signed my old one.
I've published the new certificate on keys.openpgp.org as well as on my
personal website. You can fetch it like this:
$ wget -O- https://veronneau.org/media/openpgp.key gpg --import
-----BEGIN PGP SIGNATURE-----
iQIzBAEBCgAdFiEEZ39U8fqGga2OwLzmeurE7GqqCpcFAmBFFM8ACgkQeurE7Gqq
CpcuchAAscAeszdtA+TlCI4YvK5nlk+nJnCnNBSnl7Et+jiNjq8kB/Fud+dWMTXC
Zag8oJkalbbxub0BT0bEAn+BiBunu58E0gd0Xq4syTbqZ5o5IN17S/tfxCD0k1hf
ewrnYZ2l0i5g4YvHGKC+Xv4D+Z84BylnIRaXHqlUdluOVfVYDfLybOAqoktO/KUH
I+vQBwXj0Fr/QAtgiz5Nwh/YHFiU9xMSvr5ozRwAFs6+xfIqFHuVPRRkEN5iVo4D
kkMIz+kFfkoh4aWIP4dgAu39XnEgxwTR9J+4yE8TzCCMzO7xCK0X6vqgPAxYMPvb
RuP4FnGWOnGnlcudCUAUkOaryrwRi+dPQTnNICHTYsvVc7dg+W0EhVUkwEuuEwpI
qtcB/Y5AGhqK0Cc11uXiFjIQwLTgwcUez4F0xrGeqsTtAM5gyRup2w0jbocTuYSh
ZRv/2zwrq/S3xVrUYGqdT+L5odmkBzz9zOwY5WlU2H9CMFOdh71XOv9wWQXan9ou
hLRodeOQ8MinIBP+sX36ol1zg/aP7mCHvRRSBzWt7l3WhVxgZFpNwIfp/RZqU0R4
IEq48mntFhPvHJjFmAKLKK/ckzNMtSn+HWQPJV3HTInKCTu5PTNMU3SAvPHOHEps
V6WWSOPB+1Lm/tlIULDc+0SopWoiWO4NObCSs8zMZHlYPBk5x/KIdQQBFgoAHRYh
BMqnQAcHqBawIC/DzfQlelCyHPqFBQJgRRTPAAoJEPQlelCyHPqFFVEA/1qScaAk
O+eBEE4q0BaJDsqweCS1XCcuQGkQCKi5Zv6kAQChQ96Ve7cKbN/wRkT9pdIhmx01
+CmIsnp3k6N0ZYLLCg==
=onl0
-----END PGP SIGNATURE-----
As my contributions to Debian continue to grow in number, I find myself
uploading to the archive more and more often.
Although I'm pretty happy with my current sbuild-based workflow, twice in the
past few weeks I inadvertently made a binary upload instead of a source-only
one.1
As it turns out, I am not the only DD who has had this problem before. As
Nicolas Dandrimont kindly pointed to me, dput-ng supports pre and post
upload hooks that can be used to lint your uploads. Even better, it also ships
with a check-debs hook that lets you block binary uploads.
Pretty neat, right? In a perfect world, enabling the hook would only be a matter
of adding it in the hook list of /etc/dput.d/metas/debian.json and using the
following defaults:
Sadly, bug #983160 currently makes this whole setup more complex than
it should be and forces me to use two different dput-ng profiles pointing to
two different files in /etc/dput.d/metas: a default source-only one
(ftp-master) and a binary upload one (ftp-master-binary).
Otherwise, one could use a single profile that disallows binary uploads and when
needed, override the hook using something like this:
I did start debugging the --override issue in dput-ng, but I'm not sure I'll
have time to submit a patch anytime soon. In the meantime, I'm happy to report I
shouldn't be uploading the wrong .changes file by mistake again!
Thanks to Holger Levsen and Adrian Bunk for catching those and
notifying me.
The Fated Sky is a sequel to The
Calculating Stars, but you could start with this book if you wanted to.
It would be obvious you'd missed a previous book in the series, and some
of the relationships would begin in medias res, but the story is
sufficiently self-contained that one could puzzle through.
Mild spoilers follow for The Calculating Stars, although only to
the extent of confirming that book didn't take an unexpected turn, and
nothing that wouldn't already be spoiled if you had read the short story
"The
Lady Astronaut of Mars" that kicked this series off. (The short story
takes place well after all of the books.) Also some minor spoilers for
the first section of the book, since I have to talk about its outcome in
broad strokes in order to describe the primary shape of the novel.
In the aftermath of worsening weather conditions caused by the Meteor,
humans have established a permanent base on the Moon and are preparing a
mission to Mars. Elma is not involved in the latter at the start of the
book; she's working as a shuttle pilot on the Moon, rotating periodically
back to Earth. But the political situation on Earth is becoming more
tense as the refugee crisis escalates and the weather worsens, and the
Mars mission is in danger of having its funding pulled in favor of other
priorities. Elma's success in public outreach for the space program as
the Lady Astronaut, enhanced by her navigation of a hostage situation when
an Earth re-entry goes off course and is met by armed terrorists, may be
the political edge supporters of the mission need.
The first part of this book is the hostage situation and other ground-side
politics, but the meat of this story is the tense drama of experimental,
pre-computer space flight. For those who aren't familiar with the
previous book, this series is an alternate history in which a huge
meteorite hit the Atlantic seaboard in 1952, potentially setting off
runaway global warming and accelerating the space program by more than a
decade. The Calculating Stars was primarily about the politics
surrounding the space program. In The Fated Sky, we see far more
of the technical details: the triumphs, the planning, and the accidents
and other emergencies that each could be fatal in an experimental
spaceship headed towards Mars. If what you were missing from the first
book was more technological challenge and realistic detail, The
Fated Sky delivers. It's edge-of-your-seat suspenseful and almost
impossible to put down.
I have more complicated feelings about the secondary plot. In The
Calculating Stars, the heart of the book was an incredibly well-told
story of Elma learning to deal with her social anxiety. That's still a
theme here but a lesser one; Elma has better coping mechanisms now. What
The Fated Sky tackles instead is pervasive sexism and racism, and
how Elma navigates that (not always well) as a white Jewish woman.
The centrality of sexism is about the same in both books. Elma's public
outreach is tied closely to her gender and starts as a sort of publicity
stunt. The space program remains incredibly sexist in The Fated
Stars, something that Elma has to cope with but can't truly fix. If you
found the sexism in the first book irritating, you're likely to feel the
same about this installment.
Racism is more central this time, though. In The Calculating
Stars, Elma was able to help make things somewhat better for Black
colleagues. She has a much different experience in The Fated
Stars: she ends up in a privileged position that hurts her non-white
colleagues, including one of her best friends. The merits of taking a
stand on principle are ambiguous, and she chooses not to. When she later
tries to help Black astronauts, she does so in a way that's focused on her
perceptions rather than theirs and is therefore more irritating than
helpful. The opportunities she gets, in large part because she's seen as
white, unfairly hurt other people, and she has to sit with that. It's a
thoughtful and uncomfortable look at how difficult it is for a white
person to live with discomfort they can't fix and to not make it worse by
trying to wave it away or point out their own problems.
That was the positive side of this plot, although I'm still a bit wary and
would like to read a review by a Black reviewer to see how well this plot
works from their perspective. There are some other choices that I thought
landed oddly. One is that the most racist crew member, the one who sparks
the most direct conflict with the Black members of the international crew,
is a white man from South Africa, which I thought let the United States
off the hook too much and externalized the racism a bit too neatly.
Another is that the three ships of the expedition are the Ni a,
the Pinta, and the Santa Maria, and no one in the book
comments on this. Given the thoughtful racial themes of the book, I can't
imagine this is an accident, and it is in character for United States of
this novel to pick those names, but it was an odd intrusion of an
unremarked colonial symbol. This may be part of Kowal's attempt to show
that Elma is embedded in a racist and sexist world, has limited room to
maneuver, and can't solve most of the problems, which is certainly a theme
of the series. But it left me unsettled on whether this book was up to
fully handling the fraught themes Kowal is invoking.
The other part of the book I found a bit frustrating is that it never
seriously engaged with the political argument against Mars colonization,
instead treating most of the opponents of space travel as either deluded
conspiracy believers or cynical villains. Science fiction is still
arguing with William
Proxmire even though he's been dead for fifteen years and out of office
for thirty. The strong argument against a Mars colony in Elma's world is
not funding priorities; it's that even if it's successful, only a tiny
fraction of well-connected elites will escape the planet to Mars. This
argument is made in the book and Elma dismisses it as a risk she's trying
to prevent, but it is correct. There is no conceivable
technological future that leads to evacuating the Earth to Mars, but
The Fated Sky declines to grapple with the implications of that
fact.
There's more that I haven't remarked on, including an ongoing excellent
portrayal of the complicated and loving relationship between Elma and her
husband, and a surprising development in her antagonistic semi-friendship
with the sexist test pilot who becomes the mission captain. I liked how
Kowal balanced technical problems with social problems on the long Mars
flight; both are serious concerns and they interact with each other in
complicated ways.
The details of the perils and joys of manned space flight are excellent,
at least so far as I can tell without having done the research that Kowal
did. If you want a fictionalized Apollo 13 with higher stakes and
less ground support, look no further; this is engrossing stuff. The
interpersonal politics and sociology were also fascinating and gripping,
but unsettling, in both good ways and bad. I like the challenge that
Kowal presents to a white reader, although I'm not sure she was completely
in control of it.
Cautiously recommended, although be aware that you'll need to grapple with
a sexist and racist society while reading it. Also a content note for
somewhat graphic gastrointestinal problems.
Followed by The Relentless Moon.
Rating: 8 out of 10
When I started my Master's degree in January 2018, I was confident I would be
done in a year and half. After all, I only had one year of classes and I
figured 6 months to write a thesis would be plenty.
Three years later, I'm finally done: the final version of my thesis was
accepted on January 22nd 2021.
My thesis, entitled What are the incentive structures of Free Software? An
economic analysis of Free Software's specific development model, can be found
here1. If you care about such things, both the data and the final
document can be built from source with the code in this git repository.
Results and analysis
My thesis is divided in four main sections:
an introduction to FOSS
a chapter discussing the incentive structures of Free Software (and arguing
the so called Tragedy of the Commons isn't inevitable)
a chapter trying to use empirical data to validate the theories presented in
the previous chapter
an annex on the various FOSS business models
If you're reading this blog post, chances are you'll find both section 1 and 4
a tad boring, as you might already be familiar with these concepts.
Incentives
So, why do people contribute to Free Software? Unsurprisingly, it's
complicated. Many economists have studied this topic, but for some reason, most
research happened in the early 2000s.
Although papers don't all agree with each other and most importantly, about the
variables' importance, the main incentives2 can be summarized by:
expectation of monetary gain
writing FOSS as a hobby (that includes scratching your own itch )
liking the FOSS community and feeling a sense of belonging
altruism (writing FOSS for Good )
Giving weights to these variables is not an easy thing: the FOSS ecosystem is
highly heterogeneous and thus, people tend to write FOSS for different reasons.
Moreover, incentives tend to shift with time as the ecosystem does. People
writing Free Software in the 1990s probably did it for different reasons than
people in 2021.
These four variables can also be divided in two general categories: extrinsic
and intrinsic incentives. Monetary gain expectancy is an extrinsic incentive
(its value is delayed and mediated), whereas the three other ones are intrinsic
(they have an immediate value by themselves).
Empirical analysis
Theory is nice, but it's even better when you can back it up with data. Sadly,
most of the papers on the economic incentives of FOSS are either purely
theoretical, or use sample sizes so small they could as well be.
Using the data from the StackOverflow 2018 survey, I thus
tried to see if I could somehow confirm my previous assumptions.
With 129 questions and more than 100 000 respondents (which after statistical
processing yields between 28 000 and 39 000 observations per variable of
interest), the StackOverflow 2018 survey is a very large dataset compared to
what economists are used to work with.
Sadly, it wasn't entirely enough to come up with hard answers. There is a
strong and significant correlation between writing Free Software and having a
higher salary, but endogeneity problems3 made it hard to give a
reliable estimate of how much money this would represent. Same goes for writing
code has a hobby: it seems there is a strong and significant correlation, but
the exact numbers I came up with cannot really be trusted.
The results on community as an incentive to writing FOSS were the ones that
surprised me the most. Although I expected the relation to be quite strong, the
coefficients predicted were in fact quite small. I theorise this is partly due
to only 8% of the respondents declaring they didn't feel like they belonged in
the IT community. With such a high level of adherence, the margin for
improvement has to be smaller.
As for altruism, I wasn't able get any meaningful results. In my opinion this
is mostly due to the fact there was no explicit survey question on this topic
and I tried to make up for it by cobbling data together.
Kinda anti-climatic, isn't it? I would've loved to come up with decisive
conclusions on this topic, but if there's one thing I learned while writing
this thesis, it is I don't know much after all.
Note that the thesis is written in French.
Of course, life is complex and so are people's motivations. One
could come up with dozen more reasons why people contribute to Free Software.
The "fun" of theoretical modelisation is trying to make complex things
somewhat simpler.
I'll spare you the details, but this means there is no way to
know if this correlation is the result of a causal link between the two
variables. There are ways to deal with this problem (using an instrumental
variables model is a very popular one), but again, the survey didn't
provide the proper instruments to do so. For example, it could very well be
the correlation is due to omitted variables. If you are interested in this
topic (and can read French), I talk about this issue in section 3.2.8.
In 2019, I got curious and asked Soci t de Transport de Montr al, Montreal's
transit agency, for the foot traffic data of Montreal's subway.
Since then, two years has passed and with COVID-19 still going strong, I wanted
to see what impact the pandemic had had. And oh boy, what an impact it is.
So here it is, data from 2001 to 2020, graphed the same way as in the original
2019 blog post. I could certainly juice this data, graph the pandemic
using daily figures and come up with a long and interesting blog post analysing
the main trends. I start teaching next Monday though and I still have prep work
to do, so I'll leave that to someone else.
By clicking on a subway station, you'll be redirected to a graph of the
station's foot traffic.
The R code I wrote is licensed under the GPLv3+. Feel free to reuse it
and write something nice about how the pandemic impacted the STM. I've made
small changes to the 2019 version, but it's mostly the same thing.
I have been a Puppet user for a couple of years now, first at work, and
eventually for my personal servers and computers. Although it can have a steep
learning curve, I find Puppet both nimble and very powerful. I also prefer it
to Ansible for its speed and the agent-server model it uses.
Sadly, Puppet Labs hasn't been the most supportive upstream and tends to move
pretty fast. Major versions rarely last for a whole Debian Stable release and
the upstream .deb packages are full of vendored libraries.1
Since 2017, Apollon Oikonomopoulos has been the one doing most of the work on
Puppet in Debian. Sadly, he's had less time for that lately and with Puppet 5
being deprecated in January 2021, Thomas Goirand, Utkarsh Gupta and I have been
trying to package Puppet 6 in Debian for the last 6 months.
With Puppet 6, the old ruby Puppet server using Passenger is not supported
anymore and has been replaced by puppetserver, written in Clojure and running
on the JVM. That's quite a large change and although puppetserver does reuse
some of the Clojure libraries puppetdb (already in Debian) uses, packaging it
meant quite a lot of work.
Work in the Clojure team
As part of my efforts to package puppetserver, I had the pleasure to join the
Clojure team and learn a lot about the Clojure ecosystem.
As I mentioned earlier, a lot of the Clojure dependencies needed for
puppetserver were already in the archive. Unfortunately, when Apollon
Oikonomopoulos packaged them, the leiningen build tool hadn't been packaged
yet. This meant I had to rebuild a lot of packages, on top of packaging some
new ones.
Since then, thanks to the efforts of Elana Hashman, leiningen has been
packaged and lets us run the upstream testsuites and create .jar artifacts
closer to those upstream releases.
During my work on puppetserver, I worked on the following packages:
List of packages
backport9
bidi-clojure
clj-digest-clojure
clj-helper
clj-time-clojure
clj-yaml-clojure
cljx-clojure
core-async-clojure
core-cache-clojure
core-match-clojure
cpath-clojure
crypto-equality-clojure
crypto-random-clojure
data-csv-clojure
data-json-clojure
data-priority-map-clojure
java-classpath-clojure
jnr-constants
jnr-enxio
jruby
jruby-utils-clojure
kitchensink-clojure
lazymap-clojure
liberator-clojure
ordered-clojure
pathetic-clojure
potemkin-clojure
prismatic-plumbing-clojure
prismatic-schema-clojure
puppetlabs-http-client-clojure
puppetlabs-i18n-clojure
puppetlabs-ring-middleware-clojure
puppetserver
raynes-fs-clojure
riddley-clojure
ring-basic-authentication-clojure
ring-clojure
ring-codec-clojure
shell-utils-clojure
ssl-utils-clojure
test-check-clojure
tools-analyzer-clojure
tools-analyzer-jvm-clojure
tools-cli-clojure
tools-reader-clojure
trapperkeeper-authorization-clojure
trapperkeeper-clojure
trapperkeeper-filesystem-watcher-clojure
trapperkeeper-metrics-clojure
trapperkeeper-scheduler-clojure
trapperkeeper-webserver-jetty9-clojure
url-clojure
useful-clojure
watchtower-clojure
If you want to learn more about packaging Clojure libraries and applications,
I rewrote the Debian Clojure packaging tutorial and added a section
about the quirks of using leiningen without a dedicated dh_lein tool.
Work left to get puppetserver 6 in the archive
Unfortunately, I was not able to finish the puppetserver 6 packaging work.
It is thus unlikely it will make it in Debian Bullseye. If the issues described
below are fixed, it would be possible to to package puppetserver in
bullseye-backports though.
So what's left?
jruby
Although I tried my best (kudos to Utkarsh Gupta and Thomas Goirand for the
help), jruby in Debian is still broken. It does build properly, but the
testsuite fails with multiple errors:
there are some random java failures on a few tests (no clue why)
tests ran by raklelib/rspec.rake fail to run, maybe because the --pattern
command line option isn't compatible with our version of rake? Utkarsh seemed
to know why this happens.
jruby testsuite failures aside, I have not been able to use the jruby.deb the
package currently builds in jruby-utils-clojure (testsuite failure). I had the
same exact failure with the (more broken) jruby version that is currently in
the archive, which leads me to think this is a LOAD_PATH issue in
jruby-utils-clojure. More on that below.
To try to bypass these issues, I tried to vendorjruby into
jruby-utils-clojure. At first I understood vendoring meant including
upstream pre-built artifacts (jruby-complete.jar) and shipping them directly.
After talking with people on the #debian-mentors and #debian-ftp IRC
channels, I now understand why this isn't a good idea (and why it's not
permitted in Debian). Many thanks to the people who were patient and kind enough
to discuss this with me and give me alternatives.
As far as I now understand it, vendoring in Debian means "to have an embedded
copy of the source code in another package". Code shipped that way still needs
to be built from source. This means we need to build jruby ourselves, one way
or another. Vendoringjruby in another package thus isn't terribly helpful.
If fixing jruby the proper way isn't possible, I would suggest trying to
build the package using embedded code copies of the external libraries jruby
needs to build, instead of trying to use the Debian libraries.2 This
should make it easier to replicate what upstream does and to have a final
.jar that can be used.
jruby-utils-clojure
This package is a first-level dependency for puppetserver and is the glue
between jruby and puppetserver.
It builds fine, but the testsuite fails when using the Debian jruby package. I
think the problem is caused by a jrubyLOAD_PATH issue.
The Debian jruby package plays with the LOAD_PATH a little to try use
Debian packages instead of downloading gems from the web, as upstream jruby
does. This seems to clash with the gem-home, gem-path, and
jruby-load-path variables in the jruby-utils-clojure package. The testsuite
plays around with these variables and some Ruby libraries can't be found.
I tried to fix this, but failed. Using the upstream jruby-complete.jar instead
of the Debian jruby package, the testsuite passes fine.
This package could clearly be uploaded to NEW right now by ignoring the
testsuite failures (we're just packaging static .clj source files in the
proper location in a .jar).
puppetserver
jruby issues aside, packaging puppetserver itself is 80% done. Using the
upstream jruby-complete.jar artifact, the testsuite fails with a weird
Clojure error I'm not sure I understand, but I haven't debugged it for very
long.
Upstream uses git submodules to vendor puppet (agent), hiera (3), facter and
puppet-resource-api for the testsuite to run properly. I haven't touched that,
but I believe we can either:
link to the Debian packages
fix the Debian packages if they don't include the right files (maybe in a new
binary package that just ships part of the source code?)
Without the testsuite actually running, it's hard to know what files are needed
in those packages.
What now
Puppet 5 is now deprecated.
If you or your organisation cares about Puppet in Debian,3puppetserver
really isn't far away from making it in the archive.
Very talented Debian Developers are always eager to work on these issues and
can be contracted for very reasonable rates. If you're interested in
contracting someone to help iron out the last issues, don't hesitate to reach
out via one of the following:
As for I, I'm happy to say I got a new contract and will go back to teaching
Economics for the Winter 2021 session. I might help out with some general Debian
packaging work from time to time, but it'll be as a hobby instead of a job.
Thanks
The work I did during the last 6 weeks would be not have been possible without
the support of the Wikimedia Foundation, who were gracious enough to contract
me. My particular thanks to Faidon Liambotis, Moritz M hlenhoff and John Bond.
Many, many thanks to Rob Browning, Thomas Goirand, Elana Hashman, Utkarsh Gupta
and Apollon Oikonomopoulos for their direct and indirect help, without which
all of this wouldn't have been possible.
For example, the upstream package for the Puppet Agent vendors
OpenSSL.
One of the problems of using Ruby libraries already packaged in
Debian is that jruby currently only supports Ruby 2.5. Ruby libraries in
Debian are currently expected to work with Ruby 2.7, with the transition to
Ruby 3.0 planned after the Bullseye release.
If you run Puppet, you clearly should care: the .deb packages
upstream publishes really aren't great and I would not recommend using them.
Here s my (fifteenth) monthly update about the activities I ve done in the F/L/OSS world.
Debian
This was my 24th month of contributing to Debian.
I became a DM in late March last year and a DD last Christmas! \o/
Amongs a lot of things, this was month was crazy, hectic, adventerous, and the last of 2020 more on some parts later this month.
I finally finished my 7th semester (FTW!) and moved onto my last one! That said, I had been busy with other things but still did a bunch of Debian stuff
Here are the following things I did this month:
Debian (E)LTS
Debian Long Term Support (LTS) is a project to extend the lifetime of all Debian stable releases to (at least) 5 years. Debian LTS is not handled by the Debian security team, but by a separate group of volunteers and companies interested in making it a success.
And Debian Extended LTS (ELTS) is its sister project, extending support to the Jessie release (+2 years after LTS support).
This was my fifteenth month as a Debian LTS and sixth month as a Debian ELTS paid contributor.
I was assigned 26.00 hours for LTS and 38.25 hours for ELTS and worked on the following things:
LTS CVE Fixes and Announcements:
Issued DLA 2474-1, fixing CVE-2020-28928, for musl.
For Debian 9 Stretch, these problems have been fixed in version 1.1.16-3+deb9u1.
Issued DLA 2484-1, fixing #969126, for python-certbot.
For Debian 9 Stretch, these problems have been fixed in version 0.28.0-1~deb9u3.
Issued DLA 2487-1, fixing CVE-2020-27350, for apt.
For Debian 9 Stretch, these problems have been fixed in version 1.4.11. The update was prepared by the maintainer, Julian.
Issued DLA 2488-1, fixing CVE-2020-27351, for python-apt.
For Debian 9 Stretch, these problems have been fixed in version 1.4.2. The update was prepared by the maintainer, Julian.
Issued DLA 2495-1, fixing CVE-2020-17527, for tomcat8.
For Debian 9 Stretch, these problems have been fixed in version 8.5.54-0+deb9u5.
Issued DLA 2488-2, for python-apt.
For Debian 9 Stretch, these problems have been fixed in version 1.4.3. The update was prepared by the maintainer, Julian.
Issued DLA 2508-1, fixing CVE-2020-35730, for roundcube.
For Debian 9 Stretch, these problems have been fixed in version 1.2.3+dfsg.1-4+deb9u8. The update was prepared by the maintainer, Guilhem.
ELTS CVE Fixes and Announcements:
Issued ELA 324-1, fixing CVE-2020-28928, for musl.
For Debian 8 Jessie, these problems have been fixed in version 1.1.5-2+deb8u2.
Issued ELA 325-1, fixing CVE-2020-28896, for mutt.
For Debian 8 Jessie, these problems have been fixed in version 1.5.23-3+deb8u4.
Marked CVE-2020-17527/tomcat8 as not-affected for jessie.
Marked CVE-2020-28052/bountycastle as not-affected for jessie.
Marked CVE-2020-14394/qemu as postponed for jessie.
Marked CVE-2020-35738/wavpack as not-affected for jessie.
Marked CVE-2020-3550 3-6 /qemu as postponed for jessie.
Marked CVE-2020-3550 3-6 /qemu as postponed for stretch.
Marked CVE-2020-16093/lemonldap-ng as no-dsa for stretch.
Marked CVE-2020-27837/gdm3 as no-dsa for stretch.
Marked CVE-2020- 13987, 13988, 17437 /open-iscsi as no-dsa for stretch.
Marked CVE-2020-35450/gobby as no-dsa for stretch.
Marked CVE-2020-35728/jackson-databind as no-dsa for stretch.
Marked CVE-2020-28935/nsd as no-dsa for stretch.
Auto EOL ed libpam-tacplus, open-iscsi, wireshark, gdm3, golang-go.crypto, jackson-databind, spotweb, python-autobahn, asterisk, nsd, ruby-nokogiri, linux, and motion for jessie.
Bugs and Patches
Well, I did report some bugs and issues and also sent some patches:
Issue #44 for github-activity-readme, asking for a feature request to set custom committer s email address.
Issue #711 for git2go, reporting build failure for the library.
PR #89 for rubocop-rails_config, bumping RuboCop::Packaging to v0.5.
Issue #36 for rubocop-packaging, asking to try out mutant :)
PR #212 for cucumber-ruby-core, bumping RuboCop::Packaging to v0.5.
PR #213 for cucumber-ruby-core, enabling RuboCop::Packaging.
Issue #19 for behance, asking to relax constraints on faraday and faraday_middleware.
PR #37 for rubocop-packaging, enabling tests against ruby3.0! \o/
PR #489 for cucumber-rails, bumping RuboCop::Packaging to v0.5.
Issue #362 for nheko, reporting a crash when opening the application.
PR #1282 for paper_trail, adding RuboCop::Packaging amongst other used extensions.
Bug #978640 for nheko Debian package, reporting a crash, as a result of libfmt7 regression.
Misc and Fun
Besides squashing bugs and submitting patches, I did some other things as well!
Participated in my first Advent of Code event! :)
Whilst it was indeed fun, I didn t really complete it. No reason, really. But I ll definitely come back stronger next year, heh! :)
All the solutions thus far could be found here.
Did a couple of reviews for some PRs and triaged some bugs here and there, meh.
Also did some cloud debugging, not so fun if you ask me, but cool enough to make me want to do it again! ^_^
Worked along with pollo, zigo, ehashman, rlb, et al for puppet and puppetserver in Debian. OMG, they re so lovely! <3
Ordered some interesting books to read January onward. New year resolution? Meh, not really. Or maybe. But nah.
Also did some interesting stuff this month but can t really talk about it now. Hopefully sooooon.
A few days ago I wrote a quick patch and missed a dumb mistake that made the
program crash. When reviewing the merge request on Salsa, the problem became
immediately apparent; Gitlab's diff is much better than what git diff shows by
default in a terminal.
Well, it turns out since version 2.9, git bundles a better pager,
diff-highlight. la Gitlab, it will highlight what changed in the line.
Sadly, even though diff-highlight comes with the git package in Debian, it is
not built by default (925288). You will need to:
$ sudo make --directory /usr/share/doc/git/contrib/diff-highlight
You can then add this line to your .gitconfig file:
[core]pager=/usr/share/doc/git/contrib/diff-highlight/diff-highlight less --tabs=4 -RFX
If you use tig, you'll also need to add this line in your tigrc:
set diff-highlight = /usr/share/doc/git/contrib/diff-highlight/diff-highlight
I have a lot of respect for Nadia Eghbal, partly because I can't help to be
jealous of her work on the economics of Free Software1. If you are not
already familiar with Eghbal, she is the author of Roads and Bridges: The
Unseen Labor Behind Our Digital Infrastructure, a great technical
report published for the Ford Foundation in 2016. You may also have caught her
excellent keynote at LCA 2017, entitled Consider the Maintainer.
Her latest book, Working in Public: The Making and Maintenance of Open Source
Software, published by Stripe Press a few months ago, is a great read and if
this topic interests you, I highly recommend it.
The book itself is simply gorgeous; bright orange, textured hardcover binding,
thick paper, wonderful typesetting it has everything to please. Well, nearly
everything. Sadly, it is only available on Amazon, exclusively in the United
States. A real let down for a book on Free and Open Source Software.
The book is divided in five chapters, namely:
Github as a Platform
The Structure of an Open Source Project
Roles, Incentives and Relationships
The Work Required by Software
Managing the Costs of Production
Contrary to what I was expecting, the book feels more like an extension of the
LCA keynote I previously mentioned than Roads and Bridges. Indeed, as made
apparent by the following quote, Eghbal doesn't believe funding to be the
primary problem of FOSS anymore:
We still don't have a common understanding about who's doing the work,
why they do it, and what work needs to be done. Only when we understand
the underlying behavioral dynamics of open source today, and how it differs
from its early origins, can we figure out where money fits in. Otherwise,
we're just flinging wet paper towels at a brick wall, hoping that something
sticks. p.184
That is to say, the behavior of maintainers and the challenges they face not
the eternal money problem is the real topic of this book. And it feels
refreshing. When was the last time you read something on the economics of Free
Software without it being mostly about what licences projects should pick and
how business models can be tacked on them? I certainly can't.
To be clear, I'm not sure I agree with Eghbal on this. Her having worked at
Github for a few years and having interviewed mostly people in the Ruby on
Rails and Javascript communities certainly shows in the form of a strong
selection bias. As she herself admits, this is a book on how software on
Github is produced. As much as this choice irks me (the Free Software
community certainly cannot be reduced to Github), this exercise had the merit
of forcing me to look at my own selection biases.
As such, reading Working in Public did to me something I wasn't expecting it
to do: it broke my Free Software echo chamber. Although I consider myself very
familiar with the world of Free and Open Source Software, I now understand my
somewhat ill-advised contempt for certain programming languages mostly JS
skewed my understanding of what FOSS in 2020 really is.
My Free Software world very much revolves around Debian, a project with a
strong and opinionated view of Free Software, rooted in a historical and
political understanding of the term. This, Eghbal argues, is not the case for a
large swat of developers anymore. They are The Github Generation, people
attached to Github as a platform first and foremost, and who feel "Open Source"
is just a convenient way to make things.
Although I could intellectualise this, before reading the book, I didn't really
grok how communities akin to npm have been reshaping the modern FOSS
ecosystem and how different they are from Debian itself. To be honest, I am not
sure I like this tangent and it is certainly part of the reason why I had a
tendency to dismiss it as a fringe movement I could safely ignore.
Thanks to Nadia Eghbal, I come out of this reading more humble and certainly
reminded that FOSS' heterogeneity is real and should not be idly dismissed.
This book is rich in content and although I could go on (my personal notes
clock-in at around 2000 words and I certainly disagree with a number of
things), I'll stop here for now. Go and grab a copy already!
She insists on using the term open source, but I won't :)
Although I still read a lot, during my college sophomore years my reading
habits shifted from novels to more academic works. Indeed, reading dry
textbooks and economic papers for classes often kept me from reading anything
else substantial. Nowadays, I tend to binge read novels: I won't touch a book
for months on end, and suddenly, I'll read 10 novels back to back1.
At the start of a novel binge, I always follow the same ritual: I take out my
e-reader from its storage box, marvel at the fact the battery is still pretty
full, turn on the WiFi and check if there are OS updates. And I have to admit,
Kobo Inc. (now Rakuten Kobo) has done a stellar job of keeping my e-reader up
to date. I've owned this model (a Kobo Aura 1st generation) for 7
years now and I'm still running the latest version of Kobo's Linux-based OS.
Having recently had trouble updating my Nexus 5 (also manufactured 7 years ago)
to Android 102, I asked myself:
Why is my e-reader still getting regular OS updates, while Google stopped
issuing security patches for my smartphone four years ago?
To try to answer this, let us turn to economic incentives
theory.
Although not the be-all and end-all some think it is3, incentives
theory is not a bad tool to analyse this particular problem. Executives at
Google most likely followed a very business-centric logic when they decided to
drop support for the Nexus 5. Likewise, Rakuten Kobo's decision to continue
updating older devices certainly had very little to do with ethics or loyalty
to their user base.
So, what are the incentives that keep Kobo updating devices and why are they
different than smartphone manufacturers'?
A portrait of the current long-term software support offerings for smartphones and e-readers
Before delving deeper in economic theory, let's talk data. I'll be focusing on
2 brands of e-readers, Amazon's Kindle and Rakuten's Kobo. Although the
e-reader market is highly segmented and differs a lot based on geography,
Amazon was in 2015 the clear worldwide leader with 53% of the worldwide
e-reader sales, followed by Rakuten Kobo at 13%4.
On the smartphone side, I'll be differentiating between Apple's iPhones and
Android devices, taking Google as the barometer for that ecosystem. As mentioned
below, Google is sadly the leader in long-term Android software support.
Rakuten Kobo
According to their website and to this Wikipedia
table, the only e-readers Kobo has deprecated are the original
Kobo eReader and the Kobo WiFi N289, both released in 2010. This makes their
oldest still supported device the Kobo Touch, released in 2011. In my book,
that's a pretty good track record. Long-term software support does not seem to
be advertised or to be a clear selling point in their marketing.
Amazon
According to their website, Amazon has dropped support for
all 8 devices produced before the Kindle Paperwhite 2nd generation,
first sold in 2013. To put things in perspective, the first Kindle came out in
2007, 3 years before Kobo started selling devices. Like Rakuten Kobo, Amazon
does not make promises of long-term software support as part of their
marketing.
Apple
Apple has a very clear software support policy for all their
devices:
Owners of iPhone, iPad, iPod or Mac products may obtain a service and parts
from Apple or Apple service providers for five years after the product is no
longer sold or longer, where required by law.
This means in the worst-case scenario of buying an iPhone model just as it is
discontinued, one would get a minimum of 5 years of software support.
Android
Google's policy for their Android devices is to provide software support for 3
years after the launch date. If you buy a Pixel device just
before the new one launches, you could theoretically only get 2 years of
support. In 2018, Google decided OEMs would have to provide security updates
for at least 2 years after launch, threatening not to license
Google Apps and the Play Store if they didn't comply.
A question of cost structure
From the previous section, we can conclude that in general, e-readers seem to
be supported longer than smartphones, and that Apple does a better job than
Android OEMs, providing support for about twice as long.
Even Fairphone, who's entire business is to build phones designed to last and
to be repaired was not able to keep the Fairphone 1 (2013) updated for more
than a couple years and seems to be struggling to keep the
Fairphone 2 (2015) running an up to date version of Android.
Anyone who has ever worked in IT will tell you: maintaining software over time
is hard work and hard work by specialised workers is expensive. Most commercial
electronic devices are sold and developed by for-profit enterprises and
software support all comes down to a question of cost structure. If companies
like Google or Fairphone are to be expected to provide long-term support for
the devices they manufacture, they have to be able to fund their work somehow.
In a perfect world, people would be paying for the cost of said long-term
support, as it would likely be cheaper then buying new devices every few years
and would certainly be better for the planet. Problem is, manufacturers aren't
making them pay for it.
Economists call this type of problem externalities: things that should be
part of the cost of a good, but aren't for one a reason or another. A classic
example of an externality is pollution. Clearly pollution is bad and leads to
horrendous consequences, like climate change. Sane people agree we should
drastically cut our greenhouse gas emissions, and yet, we aren't.
Neo-classical economic theory argues the way to fix externalities like
pollution is to internalise these costs, in other words, to make people pay
for the "real price" of the goods they buy. In the case of climate change and
pollution, neo-classical economic theory is plain wrong (spoiler alert: it
often is), but this is where band-aids like the carbon tax comes from.
Still, coming back to long-term software support, let's see what would happen
if we were to try to internalise software maintenance costs. We can do this
multiple ways.
1 - Include the price of software maintenance in the cost of the device
This is the choice Fairphone makes. This might somewhat work out for them since
they are a very small company, but it cannot scale for the following reasons:
This strategy relies on you giving your money to an enterprise now,
and trusting them to "Do the right thing" years later. As the years
go by, they will eventually look at their books, see how much ongoing
maintenance is costing them, drop support for the device, apologise and move
on. That is to say, enterprises have a clear economic incentive to promise
long-term support and not deliver. One could argue a company's reputation
would suffer from this kind of behaviour. Maybe sometime it does, but most
often people forget. Political promises are a great example of this.
Enterprises go bankrupt all the time. Even if company X promises 15 years of
software support for their devices, if they cease to exist, your device will
stop getting updates. The internet is full of stories of IoT devices getting
bricked when the parent company goes bankrupt and their servers disappear.
This is related to point number 1: to some degree, you have a disincentive
to pay for long-term support in advance, as the future is uncertain and
there are chances you won't get the support you paid for.
Selling your devices at a higher price to cover maintenance costs does not
necessarily mean you will make more money overall raising more money to
fund maintenance costs being the goal here. To a certain point, smartphone
models are substitute goods and prices higher than market prices will
tend to drive consumers to buy cheaper ones. There is thus a disincentive to
include the price of software maintenance in the cost of the device.
People tend to be bad at rationalising the total cost of ownership over a
long period of time. Economists call this phenomenon
hyperbolic discounting. In our case, it means people are far more likely
to buy a 500$ phone each 3 years than a 1000$ phone each 10 years. Again,
this means OEMs have a clear disincentive to include the price of long-term
software maintenance in their devices.
Clearly, life is more complex than how I portrayed it: enterprises are not
perfect rational agents, altruism exists, not all enterprises aim solely for
profit maximisation, etc. Still, in a capitalist economy, enterprises wanting
to charge for software maintenance upfront have to overcome these hurdles one
way or another if they want to avoid failing.
2 - The subscription model
Another way companies can try to internalise support costs is to rely on a
subscription-based revenue model. This has multiple advantages over the previous
option, mainly:
It does not affect the initial purchase price of the device, making it easier
to sell them at a competitive price.
It provides a stable source of income, something that is very valuable to
enterprises, as it reduces overall risks. This in return creates an incentive
to continue providing software support as long as people are paying.
If this model is so interesting from an economic incentives point of view, why
isn't any smartphone manufacturer offering that kind of program? The answer is,
they are, but not explicitly5.
Apple and Google can fund part of their smartphone software support via the 30%
cut they take out of their respective app stores. A report from Sensor
Tower shows that in 2019, Apple made an estimated US$ 16 billion
from the App Store, while Google raked in US$ 9 billion from the Google Play
Store. Although the Fortune 500 ranking tells us this respectively
is "only" 5.6% and 6.5% of their gross annual revenue for 2019, the profit
margins in this category are certainly higher than any of their other products.
This means Google and Apple have an important incentive to keep your device
updated for some time: if your device works well and is updated, you are more
likely to keep buying apps from their store. When software support for a device
stops, there is a risk paying customers will buy a competitor device and leave
their ecosystem.
This also explains why OEMs who don't own app stores tend not to provide
software support for very long periods of time. Most of them only make money
when you buy a new phone. Providing long-term software support thus becomes a
disincentive, as it directly reduces their sale revenues.
Same goes for Kindles and Kobos: the longer your device works, the more money
they make with their electronic book stores. In my opinion, it's likely Amazon
and Rakuten Kobo produce quarterly cost-benefit reports to decide when to drop
support for older devices, based on ongoing support costs and the recurring
revenues these devices bring in.
Rakuten Kobo is also in a more precarious situation than Amazon is: considering
Amazon's very important market share, if your device stops getting new updates,
there is a greater chance people will replace their old Kobo with a Kindle.
Again, they have an important economic incentive to keep devices running as long
as they are profitable.
Can Free Software fix this?
Yes and no. Free Software certainly isn't a magic wand one can wave to make
everything better, but does provide major advantages in terms of security, user
freedom and sometimes costs. The last piece of the puzzle explaining why Rakuten
Kobo's software support is better than Google's is technological choices.
Smartphones are incredibly complex devices and have become the main computing
platform of many. Similar to the web, there is a race for features and
complexity that tends to create bloat and make older devices slow and painful
to use. On the other hand, e-readers are simpler devices built for a single
task: display electronic books.
Control over the platform is also a key aspect of the cost structure of
providing software updates. Whereas Apple controls both the software and
hardware side of iPhones, Android is a sad mess of drivers and SoCs, all
providing different levels of support over time6.
If you take a look at the platforms the Kindle and Kobo are built on, you'll
quickly see they both use Freescale I.MX SoCs. These processors
are well known for their excellent upstream support in the Linux kernel and
their relative longevity, chips being produced for either 10 or 15 years. This
in turn makes updates much easier and less expensive to provide.
So clearly, open architectures, free drivers and open hardware helps
tremendously, but aren't enough on their own. One of the lessons we must learn
from the (amazing) LineageOS project is how lack of funding hurts everyone.
If there is no one to do the volunteer work required to maintain a version of
LOS for your device, it won't be supported. Worse, when purchasing a new
device, users cannot know in advance how many years of LOS support they will
get. This makes buying new devices a frustrating hit-and-miss experience. If
you are lucky, you will get many years of support. Otherwise, you risk
your device becoming an expensive insecure paperweight.
So how do we fix this? Anyone with a brain understands throwing away perfectly
good devices each 2 years is not sustainable. Government regulations enforcing
a minimum support life would be a step in the right direction, but at the end
of the day, Capitalism is to blame. Like the aforementioned carbon tax, band-aid
solutions can make things somewhat better, but won't fix our current economic
system's underlying problems.
For now though, I'll leave fixing the problem of Capitalism to someone else.
My most recent novel binge has been focused on re-reading the Dune
franchise. I first read the 6 novels written by Frank Herbert when I was 13
years old and only had vague and pleasant memories of his work. Great stuff.
I'm back on LineageOS! Nice folks released an unofficial LOS
17.1 port for the Nexus 5 last January and have kept it updated since
then. If you are to use it, I would also recommend updating TWRP to this
version specifically patched for the Nexus 5.
Very few serious economists actually believe neo-classical
rational agent theory is a satisfactory explanation of human behavior. In my
opinion, it's merely a (mostly flawed) lens to try to interpret certain
behaviors, a tool amongst others that needs to be used carefully, preferably
as part of a pluralism of approaches.
Good data on the e-reader market is hard to come by and is
mainly produced by specialised market research companies selling their
findings at very high prices. Those particular statistics come from a
MarketWatch analysis.
If they were to tell people: You need to pay us 5$/month if you
want to receive software updates, I'm sure most people would not pay. Would
you?
Coming back to Fairphones, if they had so much problems
providing an Android 9 build for the Fairphone 2, it's because Qualcomm
never provided Android 7+ support for the Snapdragon 801 SoC it
uses.
I'm happy to announce I handed out my Master's Thesis last Monday. I'm not
publishing the final copy just yet1, as it still needs to go through
the approval committee. If everything goes well, I should have my Master of
Economics diploma before Christmas!
It sure hasn't been easy, and although I regret nothing, I'm also happy to be
done with university.
Looking for a job
What an odd time to be looking for a job, right? Turns out for the first time
in 12 years, I don't have an employer. It's oddly freeing, but also a little
scary. I'm certainly not bitter about it though and it's nice to have some time
on my hands to work on various projects and read things other than academic
papers. Look out for my next blog posts on using the NeTV2 as an OSHW HDMI
capture card, on hacking at security tokens and much more!
I'm not looking for anything long term (I'm hoping to teach Economics again next
Winter), but for the next few months, my calendar is wide open.
For the last 6 years, I worked as Linux system administrator, mostly using a
LAMP stack in conjunction with Puppet, Shell and Python. Although I'm most
comfortable with Puppet, I also have decent experience with Ansible, thanks to
my work in the DebConf Videoteam.
I'm not the most seasoned Debian Developer, but I have some experience
packaging Python applications and libraries. Although I'm no expert at it,
lately I've also been working on Clojure packages, as I'm trying to get Puppet
6 in Debian in time for the Bullseye freeze. At the rate it's going though, I
doubt we're going to make it...
If your company depends on Puppet and cares about having a version in Debian 11
that is maintained (Puppet 5 is EOL in November 2020), I'm your guy!
Oh, and I guess I'm a soon-to-be Master of Economics specialising in Free and
Open Source Software business models and incentives theory. Not sure I'll ever
get paid putting that in application, but hey, who knows.
If any of that resonates with you, contact me and let's have a chat! I promise
I don't bite :)
The title of the thesis is What are the incentive structures of
Free Software? An economic analysis of Free Software's specific development
model. Once the final copy is approved, I'll be sure to write a longer blog
post about my findings here.
Dealing with the void during MiniDebConf Online #1
Between 28 and 31 May this year, we set out to create our first ever online MiniDebConf for Debian. Many people have been meaning to do something similar for a long time, but it just didn t work out yet. With many of us being in lock down due to COVID-19, and with the strong possibility looming that DebConf20 might have had to become an online event, we rushed towards organising the first ever Online MiniDebConf and put together some form of usable video stack for it.
I could go into all kinds of details on the above, but this post is about a bug that lead to a pretty nifty feature for DebConf20. The tool that we use to capture Jitsi calls is called Jibri (Jitsi Broadcasting Infrustructure). It had a bug (well, bug for us, but it s an upstream feature) where Jibri would hang up after 30s of complete silence, because it would assume that the call has ended and that the worker can be freed up again. This would result in the stream being ended at the end of every talk, so before the next talk, someone would have to remember to press play again in their media player or on the video player on the stream page. Hrmph.
Easy solution on the morning that the conference starts? I was testing a Debian Live image the night before in a KVM and thought that I might as well just start a Jitsi call from there and keep a steady stream of silence so that Jibri doesn t hang up.
It worked! But the black screen and silence on stream was a bit eery. Because this event was so experimental in nature, and because we were on such an incredibly tight timeline, we opted not to seek sponsors for this event, so there was no sponsors loop that we d usually stream during a DebConf event. Then I thought Ah! I could just show the schedule! .
The stream looked bright and colourful (and was even useful!) and Jitsi/Jibri didn t die. I thought my work was done. As usual, little did I know how untrue that was.
The silence was slightly disturbing after the talks, and people asked for some music. Playing music on my VM and capturing the desktop audio in to Jitsi was just a few pulseaudio settings away, so I spent two minutes finding some freely licensed tracks that sounded ok enough to just start playing on the stream. I came across mini-albums by Captive Portal and Cinema Noir, During the course of the MiniDebConf Online I even started enjoying those. Someone also pointed out that it would be really nice to have a UTC clock on the stream. I couldn t find a nice clock in a hurry so I just added a tmux clock in the meantime while we deal with the real-time torrent of issues that usually happens when organising events like this.
Speaking of issues, during our very first talk of the last day, our speaker had a power cut during the talk and abruptly dropped off. Oops! So, since I had a screenshare open from the VM to the stream, I thought I d just pop in a quick message in a text editor to let people know that we re aware of it and trying to figure out what s going on.
In the end, MiniDebConf Online worked out all right. Besides the power cut for our one speaker, and another who had a laptop that was way too under-powered to deal with video, everything worked out very well. Even the issues we had weren t show-stoppers and we managed to work around them.
DebConf20 Moves Online
For DebConf, we usually show a sponsors loop in between sessions. It s great that we give our sponsors visibility here, but in reality people see the sponsors loop and think Talk over! and then they look away. It s also completely silent and doesn t provide any additional useful information. I was wondering how I could take our lessons from MDCO#1 and integrate our new tricks with the sponsors loop. That is, add the schedule, time, some space to type announcements on the screen and also add some loopable music to it.
I used OBS before in making my videos, and like the flexibility it provides when working with scenes and sources. A scene is what you would think of as a screen or a document with its own collection of sources or elements. For example, a scene might contain sources such as a logo, clock, video, image, etc. A scene can also contain another scene. This is useful if you want to contain a banner or play some background music that is shared between scenes.
The above screenshots illustrate some basics of scenes and sources. First with just the DC20 banner, and then that used embedded in another scene.
For MDCO#1, I copied and pasted the schedule into a LibreOffice Impress slide that was displayed on the stream. Having to do this for all 7 days of DebConf, plus dealing with scheduling changes would be daunting. So, I started to look in to generating some schedule slides programmatically. Stefano then pointed me to the Happening Now page on the DebConf website, where the current schedule block is displayed. So all I would need to do in OBS was to display a web page. Nice!
Unfortunately the OBS in Debian doesn t have the ability to display web pages out of the box (we need to figure out CEF in Debian), but fortunately someone provides a pre-compiled version of the plugin called Linux Browser that works just fine. This allowed me to easily add the schedule page in its own scene.
Being able to display a web page solved another problem. I wasn t fond of having to type / manage the announcements in OBS. It would either be a bit prone to user error, and if you want to edit the text while the loop is running, you d have to disrupt the loop, go to the foreground scene, and edit the text before resuming the loop. That s a bit icky. Then I thought that we could probably just get that from a web page instead. We could host some nice html snippet in a repository in salsa, and then anyone could easily commit an MR to update the announcement.
But then I went a step further, use an etherpad! Then anyone in the orga team can quickly update the announcement and it would be instantly changed on the stream. Nice! So that small section of announcement text on the screen is actually a whole web browser with an added OBS filter to crop away all the pieces we don t want. Overkill? Sure, but it gave us a decent enough solution that worked in time for the start of DebConf. Also, being able to type directly on to the loop screen works out great especially in an emergency. Oh, and uhm the clock is also a website rendered in its own web browser :-P
So, I had the ability to make scenes, add elements and add all the minimal elements I wanted in there. Great! But now I had to figure out how to switch scenes automatically. It s probably worth mentioning that I only found some time to really dig into this right before DebConf started, so with all of this I was scrambling to find things that would work without too many bugs while also still being practical.
Now I needed the ability to switch between the scenes automatically / programmatically. I had never done this in OBS before. I know it has some API because there are Android apps that you can use to control OBS with from your phone. I discovered that it had an automatic scene switcher, but it s very basic. It can only switch based on active window, which can be useful in some cases, but since we won t have any windows open other than OBS, this tool was basically pointless.
After some quick searches, I found a plugin called Advanced Scene Switcher. This plugin can do a lot more, but has some weird UI choices, and is really meant for gamers and other types of professional streamers to help them automate their work flow and doesn t seem at all meant to be used for a continuous loop, but, it worked, and I could make it do something that will work for us during the DebConf.
I had a chicken and egg problem because I had to figure out a programming flow, but didn t really have any content to work with, or an idea of all the content that we would eventually have. I ve been toying with the idea in my mind and had some idea that we could add fun facts, postcards (an image with some text), time now in different timezones, Debian news (maybe procured by the press team), cards that contain the longer announcements that was sent to debconf-announce, perhaps a shout out or two and some photos from previous DebConfs like the group photos. I knew that I wouldn t be able to build anything substantial by the time DebConf starts, but adding content to OBS in between talks is relatively easy, so we could keep on building on it during DebConf.
Nattie provided the first shout out, and I made 2 video loops with the DC18/19 pictures and also two Did you know cards. So the flow I ended up with was: Sponsors -> Happening Now -> Random video (which would be any of those clips) -> Back to sponsors. This ended up working pretty well for quite a while. With the first batch of videos the sponsor loop would come up on average about every 2 minutes, but as much shorter clips like shout outs started to come in faster and faster, it made sense to play a few 2-3 shout-outs before going back to sponsors.
So here is a very brief guide on how I set up the sequencing in Advanced Scene Switcher.
If no condition was met, a video would play from the Random tab.
Then in the Random tab, I added the scenes that were part of the random mix. Annoyingly, you have to specify how long it should play for. If you don t, the no condition thingy is triggered and another video is selected. The time is also the length of the video minus one second, because
You can t just say that a random video should return back to a certain scene, you have to specify that in the sequence tab for each video. Why after 1 second? Because, at least in my early tests, and I didn t circle back to this, it seems like 0s can randomly either mean instantly, or never. Yes, this ended up being a bit confusing and tedious, and considering the late hours I worked on this, I m surprised that I didn t manage to screw it up completely at any point.
I also suspected that threads would eventually happen. That is, when people create video replies to other videos. We had 3 threads in total. There was a backups thread, beverage thread and an impersonation thread. The arrow in the screenshot above points to the backups thread. I know it doesn t look that complicated, but it was initially somewhat confusing to set up and make sense out of it.
For the next event, the Advanced Scene Switcher might just get some more taming, or even be replaced entirely. There are ways to drive OBS by API, and even the Advanced Scene Switcher tool can be driven externally to some degree, but I think we definitely want to replace it by the next full DebConf. We had the problem that when a talk ended, we would return to the loop in the middle of a clip, which felt very unnatural and sometimes even confusing. So Stefano helped me with a helper script that could read the socket from Vocto, which I used to write either Loop or Standby to a file, and then the scene switcher would watch that file and keep the sponsors loop ready for start while the talks play. Why not just switch to sponsors when the talk ends? Well, the little bit of delay in switching would mean that you would see a tiny bit of loop every time before switching to sponsors. This is also why we didn t have any loop for the ad-hoc track (that would have probably needed another OBS instance, we ll look more into solutions for this for the future).
Then for all the clips. There were over 50 of them. All of them edited by hand in kdenlive. I removed any hard clicks, tried to improve audibility, remove some sections at the beginning and the end that seemed extra and added some music that would reduce in volume when someone speaks. In the beginning, I had lots of fun with choosing music for the clips. Towards the end, I had to rush them through and just chose the same tune whether it made sense or not. For comparison of what a difference the music can make, compare the original and adapted version for Valhalla s clip above, or this original and adapted video from urbec. This part was a lot more fun than dealing with the video sequencer, but I also want to automate it a bit. When I can fully drive OBS from Python I ll likely instead want to show those cards and control music volume from Python (what could possibly go wrong ).
The loopy name happened when I requested an @debconf.org alias for this. I was initially just thinking about loop@debconf.org but since I wanted to make it clear that the purpose of this loop is also to have some fun, I opted for loopy instead:
I was really surprised by how people took to loopy. I hoped it would be good and that it would have somewhat positive feedback, but the positive feedback was just immense. The idea was that people typically saw it in between talks. But a few people told me they kept it playing after the last talk of the day to watch it in the background. Some asked for the music because they want to keep listening to it while working (and even for jogging!?). Some people also asked for recordings of the loop because they want to keep it for after DebConf. The shoutouts idea proved to be very popular. Overall, I m very glad that people enjoyed it and I think it s safe to say that loopy will be back for the next event.
Also throughout this experiment Loopy Loop turned into yet another DebConf mascot. We gain one about every DebConf, some by accident and some on purpose. This one was not quite on purpose. I meant to make an image for it for salsa, and started with an infinite loop symbol. That s a loop, but by just adding two more solid circles to it, it looks like googly eyes, now it s a proper loopy loop!
I like the progress we ve made on this, but there s still a long way to go, and the ideas keep heaping up. The next event is quite soon (MDCO#2 at the end of November, and it seems that 3 other MiniDebConf events may also be planned), but over the next few events there will likely be significantly better graphics/artwork, better sequencing, better flow and more layout options. I hope to gain some additional members in the team to deal with incoming requests during DebConf. It was quite hectic this time! The new OBS also has a scripting host that supports Python, so I should be able to do some nice things even within OBS without having to drive it externally (like, display a clock without starting a web browser).
The Loopy Loop Music
The two mini albums that mostly played during the first few days were just a copy and paste from the MDCO#1 music, which was:
I have much more things to say about DebConf20, but I ll keep that for another post, and hopefully we can get all the other video stuff in a post from the video team, because I think there s been some real good work done for this DebConf. Also thanks to Infomaniak who was not only a platinum sponsor for this DebConf, but they also provided us with plenty of computing power to run all the video stuff on. Thanks again!
After we gave our talk at DebConf 20, Doing things together,
there were 5 minutes left for the live Q&A. Pollo asked a question that I
think is interesting and deserves a longer answer: How can we still have a
good code review process without making it a "you need to be perfect"
scenario? I often find picky code reviews help me write better code.
I find it useful to first disentangle
what code reviews are good for, how we do them, why we do them that way, and
how we can potentially improve processes.
What are code reviews good for?
Code review and peer review are great methods for cooperation aiming at:
Ensuring that the code works as intended
Ensuring that the task was fully accomplished and no detail left out
Ensuring that no security issues have been introduced
Making sure the code fits the practices of the team and is understandable and maintainable by others
Sharing insights, transferring knowledge between code author and code reviewer
Helping the code author to learn to write better code
Looking at this list, the last point seems to be more like a nice side
effect of all the other points. :)
How do code reviews happen in our communities?
It seems to be a common assumption that code reviews are and have to
be picky and perfectionist. To me, this does not actually seem to be a
necessity to accomplish the above mentioned goals. We might want to work with
precision a quality which is different from perfection. Perfection
can hardly be a goal: perfection does not exist.
Perfectionist dynamics can lead to failing to call something "good enough"
or "done". Sometimes, a disproportionate amount of time is invested in writing
(several) code reviews for minor issues. In some cases, strong perfectionist
dynamics of a reviewer can create a feeling of never being good enough along
with a loss of self esteem for otherwise skilled code authors.
When do we cross the line?
When going from cooperation, precision, and learning to write better code,
to nitpicking, we are crossing a line: nitpicking means to pedantically search
for others' faults. For example, I once got one of my Git commits at work
criticized merely for its commit message that was said to be "ugly"
because I "use[d] the same word twice" in it.
When we are nitpicking, we might not give feedback in an appreciative,
cooperative way, we become fault finders instead. From there it's a short way
to operating on the level of blame.
Are you nitpicking to help or are you nitpicking to prove something?
Motivations matter.
How can we improve code reviewing?
When we did something wrong, we can do better next time. When we are told that we are wrong, the underlying assumption is that we cannot change (See Bren Brown, The difference between blame and shame). We can learn to go beyond blame.
Negative feedback rarely leads to improvement if the
environment in which it happens lacks general appreciation and confirmation.
We can learn to give helpful feedback. It might be harder to create an
appreciative environment in which negative feedback is a possibility for
growth. One can think of it like of a relationship: in a healthy relationship
we can tell each other when something does not work and work it out because
we regularly experience that we respect, value, and support each
other.
To be able to work precisely, we need guidelines, tools, and time. It's not
possible to work with precision if we are in a hurry, burnt out, or working
under a permanent state of exception. The same is true for receiving picky
feedback.
On DebConf's IRC channel, after our talk, marvil07 said: On picky code
reviews, something that I find useful is automation on code reviews; i.e. when
a bot is stating a list of indentation/style errors it feels less personal, and
also saves time to humans to provide more insightful changes. Indeed, we can
set up routines that do automatic fault checking (linting). We can set up coding
guidelines. We can define what we call "done" or "good enough".
We can negotiate with each other how we would like code to be reviewed. For
example, one could agree that a particularly perfectionist reviewer should
point out only functional faults. They can spare their time and refrain from
writing lengthy reviews about minor esthetic issues that have never made it
into a guideline. If necessary, author and reviewer can talk about what can be
improved on the long term during a retrospective. Or, on the contrary, one could explicitly
ask for a particularly detailed review including all sorts of esthetic
issues to learn the best practices of a team applied to one's own code.
In summary: let's not lose sight of what code reviews are good for, let's
have a clear definition of "done", let's not confuse precision with perfection,
let's create appreciative work environments, and negotiate with each
other how reviews are made.
I'm sure you will come up with more ideas. Please do not hesitate to share them!
Our thoughts about cooperation aspects of doing things together.
Sometimes in Debian we do work together with others, and sometimes we are a
number of people who work alone, and happen to all upload their work in the
same place.
In times when we have needed to take important decisions together, this
distinction has become crucial, and some of us might have found that we were
not as good at cooperation as we would have thought.
This talk is intended for everyone who is part of a larger community. We will
show concepts and tools that we think could help understand and shape
cooperation.
How can we still have a good code review process without making it a "you
need to be perfect" scenario? I often find picky code reviews help me write
better code.
DebConf20 starts in about 5 weeks, and as always, the DebConf
Videoteam is working hard to make sure it'll be a success. As such, we held a
sprint from July 9th to 13th to work on our new infrastructure.
A remote sprint certainly ain't as fun as an in-person one, but we nonetheless
managed to enjoy ourselves. Many thanks to those who participated, namely:
Carl Karsten (CarlFK)
Ivo De Decker (ivodd)
Kyle Robbertze (paddatrapper)
Louis-Philippe V ronneau (pollo)
Nattie Mayer-Hutchings (nattie)
Nicolas Dandrimont (olasd)
Stefano Rivera (tumbleweed)
Wouter Verhelst (wouter)
We also wish to extend our thanks to Thomas Goirand and Infomaniak for
providing us with virtual machines to experiment on and host the video
infrastructure for DebConf20.
Advice for presenters
For DebConf20, we strongly encourage presenters to record their talks in
advance and send us the resulting video. We understand this is more work,
but we think it'll make for a more agreeable conference for everyone. Video
conferencing is still pretty wonky and there is nothing worse than a talk
ruined by a flaky internet connection or hardware failures.
As such, if you are giving a talk at DebConf this year, we are asking you to
read and follow our guide on how to record your presentation.
Fear not: we are not getting rid of the Q&A period at the end of talks.
Attendees will ask their questions either on IRC or on a collaborative pad
and the Talkmeister will relay them to the speaker once the pre-recorded
video has finished playing.
New infrastructure, who dis?
Organising a virtual DebConf implies migrating from our battle-tested
on-premise workflow to a completely new remote one.
One of the major changes this means for us is the addition of Jitsi Meet to our
infrastructure. We normally have 3 different video sources in a room: two
cameras and a slides grabber. With the new online workflow, directors will be
able to play pre-recorded videos as a source, will get a feed from a Jitsi room
and will see the audience questions as a third source.
This might seem simple at first, but is in fact a very major change to our
workflow and required a lot of work to implement.
== On-premise == == Online ==
Camera 1 Jitsi
v ---> Frontend v ---> Frontend
Slides -> Voctomix -> Backend -+--> Frontend Questions -> Voctomix -> Backend -+--> Frontend
^ ---> Frontend ^ ---> Frontend
Camera 2 Pre-recorded video
In our tests, playing back pre-recorded videos to voctomix worked well, but was
sometimes unreliable due to inconsistent encoding settings. Presenters will
thus upload their pre-recorded talks to SReview so we can make sure there
aren't any obvious errors. Videos will then be re-encoded to ensure a
consistent encoding and to normalise audio levels.
This process will also let us stitch the Q&As at the end of the pre-recorded
videos more easily prior to publication.
Reducing the stream latency
One of the pitfalls of the streaming infrastructure we have been using since
2016 is high video latency. In a worst case scenario, remote attendees could
get up to 45 seconds of latency, making participation in events like BoFs
arduous.
In preparation for DebConf20, we added a new way to stream our talks: RTMP.
Attendees will thus have the option of using either an HLS stream with higher
latency or an RTMP stream with lower latency.
Here is a comparative table that can help you decide between the two protocols:
HLS
RTMP
Pros
Can be watched from a browser
Auto-selects a stream encoding
Single URL to remember
Lower latency (~5s)
Cons
Higher latency (up to 45s)
Requires a dedicated video player (VLC, mpv)
Specific URLs for each encoding setting
Live mixing from home with VoctoWeb
Since DebConf16, we have been using voctomix, a live video mixer developed
by the CCC VOC. voctomix is conveniently divided in two: voctocore is the
backend server while voctogui is a GTK+ UI frontend directors can use to
live-mix.
Although voctogui can connect to a remote server, it was primarily designed to
run either on the same machine as voctocore or on the same LAN. Trying to use
voctogui from a machine at home to connect to a voctocore running in a
datacenter proved unreliable, especially for high-latency and low bandwidth
connections.
Inspired by the setup FOSDEM uses, we instead decided to go with a web frontend
for voctocore. We initially used FOSDEM's code as a proof of
concept, but quickly reimplemented it in Python, a language we are more
familiar with as a team.
Compared to the FOSDEM PHP implementation, voctoweb implements A / B source
selection (akin to voctogui) as well as audio control, two very useful
features. In the following screen captures, you can see the old PHP UI on the
left and the new shiny Python one on the right.
Voctoweb is still under development and is likely to change quite a bit
until DebConf20. Still, the current version seems to works well enough to be
used in production if you ever need to.
Python GeoIP redirector
We run multiple geographically-distributed streaming frontend servers to
minimize the load on our streaming backend and to reduce overall latency.
Although users can connect to the frontends directly, we typically point them
to live.debconf.org and redirect connections to the nearest server.
Sadly, 6 months ago MaxMind decided to change the licence on their
GeoLite2 database and left us scrambling. To fix this annoying issue, Stefano
Rivera wrote a Python program that uses the new database and reworked our
ansible frontend server role. Since the new database cannot be
redistributed freely, you'll have to get a (free) license key from MaxMind if
you to use this role.
Ansible & CI improvements
Infrastructure as code is a living process and needs constant care to fix bugs,
follow changes in DSL and to implement new features. All that to say a large
part of the sprint was spent making our ansible roles and continuous
integration setup more reliable, less buggy and more featureful.
All in all, we merged 26 separate ansible-related merge request during the
sprint! As always, if you are good with ansible and wish to help, we accept
merge requests on our ansible repository :)
DebConf20 will be held online this year and I've started doing some work
for the DebConf videoteam to prepare what's to come.
One thing I want us to do is capture a live IRC session and use it as a video
input in Voctomix, the live video mixer we use. This way, at the end of a
talk we could show both the attendees asking questions on IRC and the presenter
replying to them side-by-side.
Capturing a live video of an IRC client on a remote headless server is somewhat
more complicated than you might think; as far as I know, neither ffmpeg nor
gstreamer support recording a live ssh pseudoterminal1.
Worse, neither weechat nor irssi run on X: they use ncurses... Although you
can capture an X11 window with ffmpeg -f x11grab, I wasn't able to get them to
run with Xvfb.
Capturing the framebuffer
One thing I dislike with this method is the framebuffer isn't always easy to
access on remote machines. If you don't have a serial connection, you can try
using a VNC server that can.
I did my tests in a VM on an KVM hypervisor and used virt-manager to access
the framebuffer.
I had a hard time setting the framebuffer resolution to a 16:9 aspect ratio. The
winning combination ended up passing the nomodeset kernel parameter at boot
and setting up these parameters in /etc/default/grub2:
GRUB_GFXMODE=1280x720
GRUB_GFXPAYLOAD_LINUX=keep
To make the text more readable, this is the /etc/default/console-setup file
that seemed to make the most sense:
# CONFIGURATION FILE FOR SETUPCON
# Consult the console-setup(5) manual page.
ACTIVE_CONSOLES="/dev/tty[1-6]"
CHARMAP="UTF-8"
CODESET="Lat15"
FONTFACE="TerminusBold"
FONTSIZE="12x24"
Once that is done, the only thing left is to run the IRC client and launch
ffmpeg. The magic command to record the framebuffer seems to be something
like:
 I've been using
I've been using 
 We fixed a couple of
We fixed a couple of 

 Sadly, even though
Sadly, even though  Contrary to what I was expecting, the book feels more like an extension of the
LCA keynote I previously mentioned than Roads and Bridges. Indeed, as made
apparent by the following quote, Eghbal doesn't believe funding to be the
primary problem of FOSS anymore:
Contrary to what I was expecting, the book feels more like an extension of the
LCA keynote I previously mentioned than Roads and Bridges. Indeed, as made
apparent by the following quote, Eghbal doesn't believe funding to be the
primary problem of FOSS anymore:



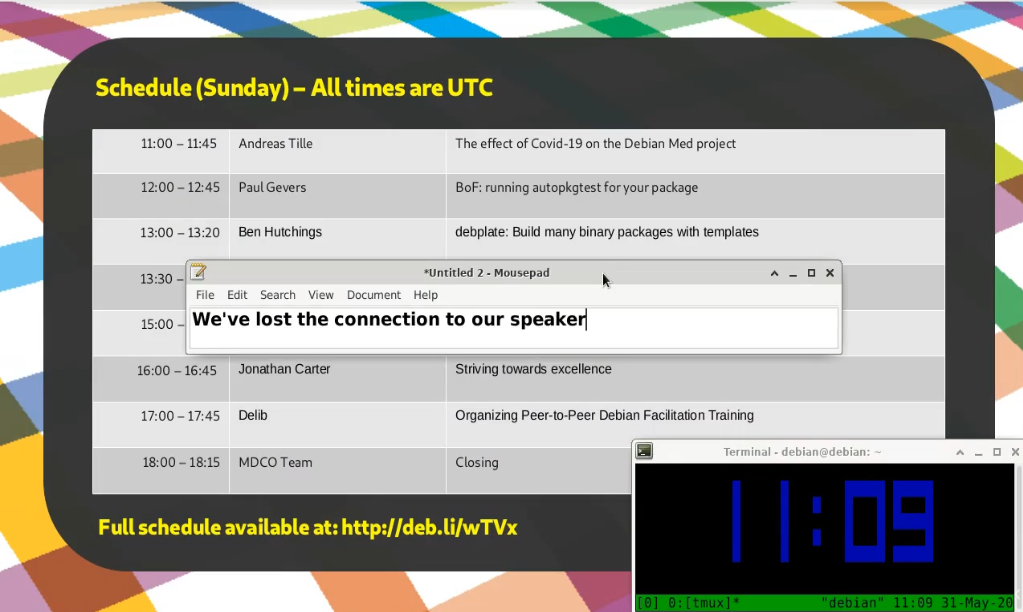
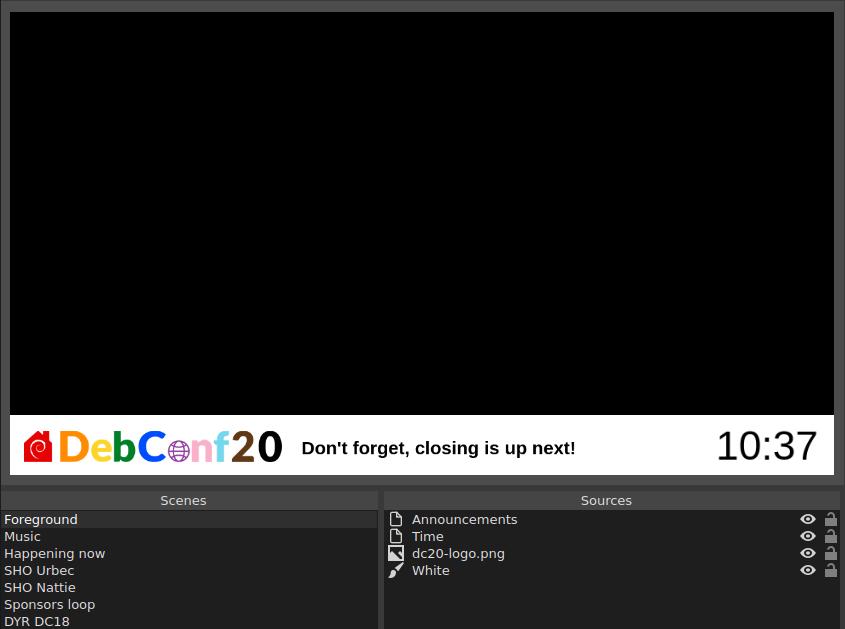
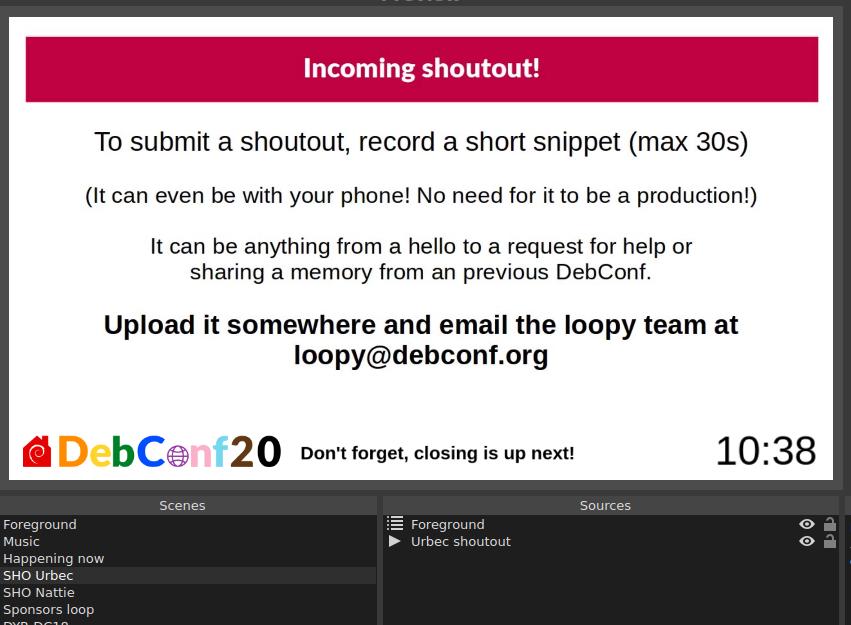
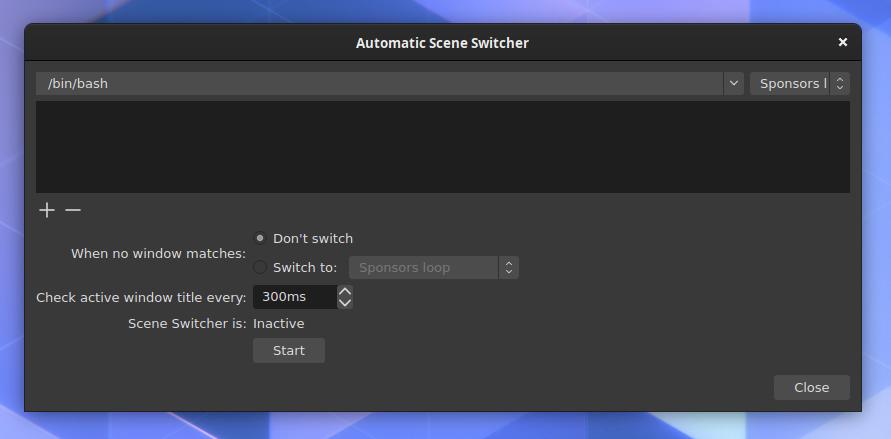
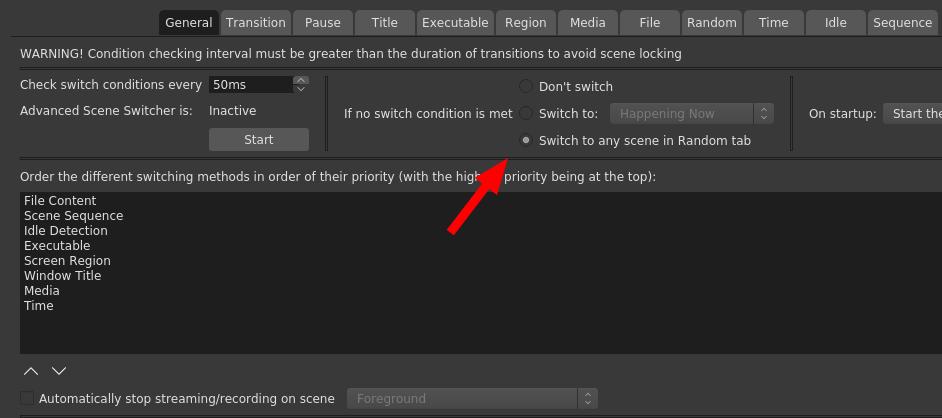
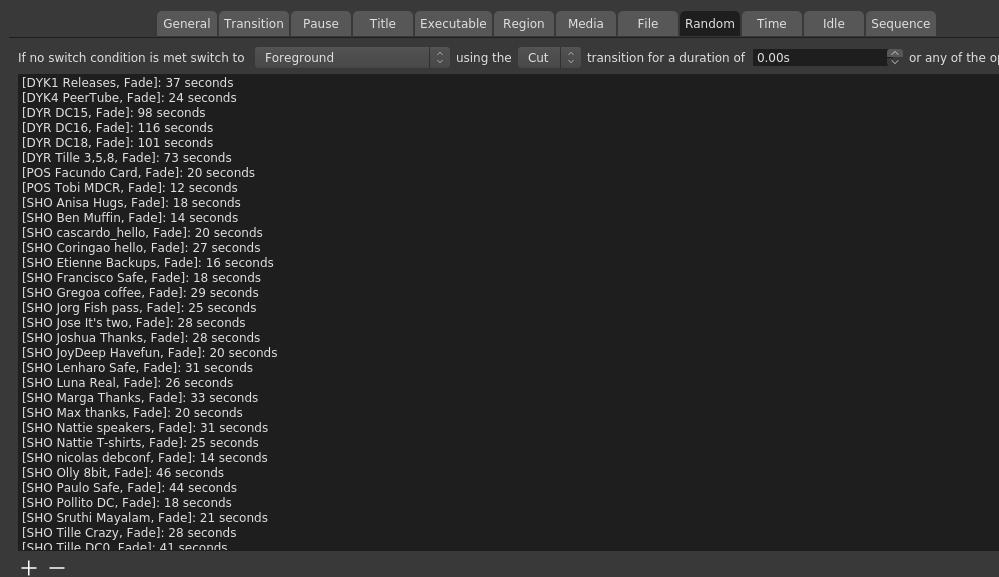
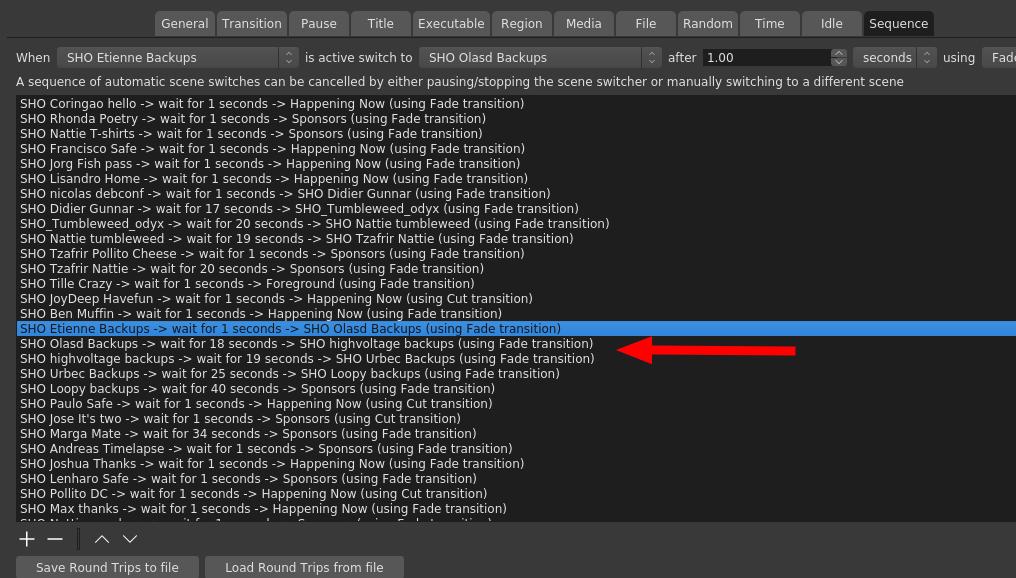
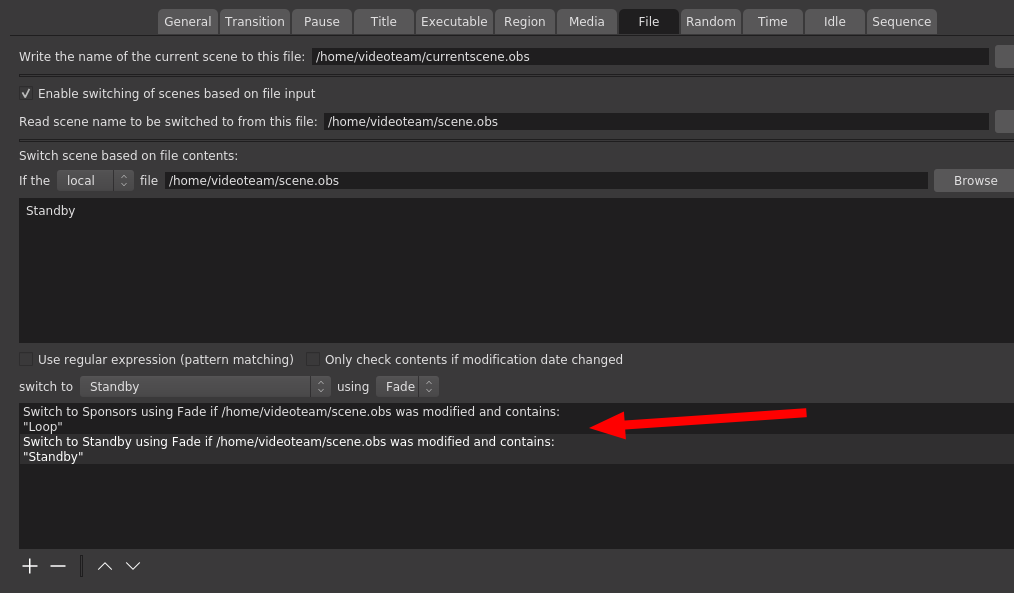

 After we gave our talk at DebConf 20,
After we gave our talk at DebConf 20, 

 Capturing a live video of an IRC client on a remote headless server is somewhat
more complicated than you might think; as far as I know, neither
Capturing a live video of an IRC client on a remote headless server is somewhat
more complicated than you might think; as far as I know, neither {kind=link}
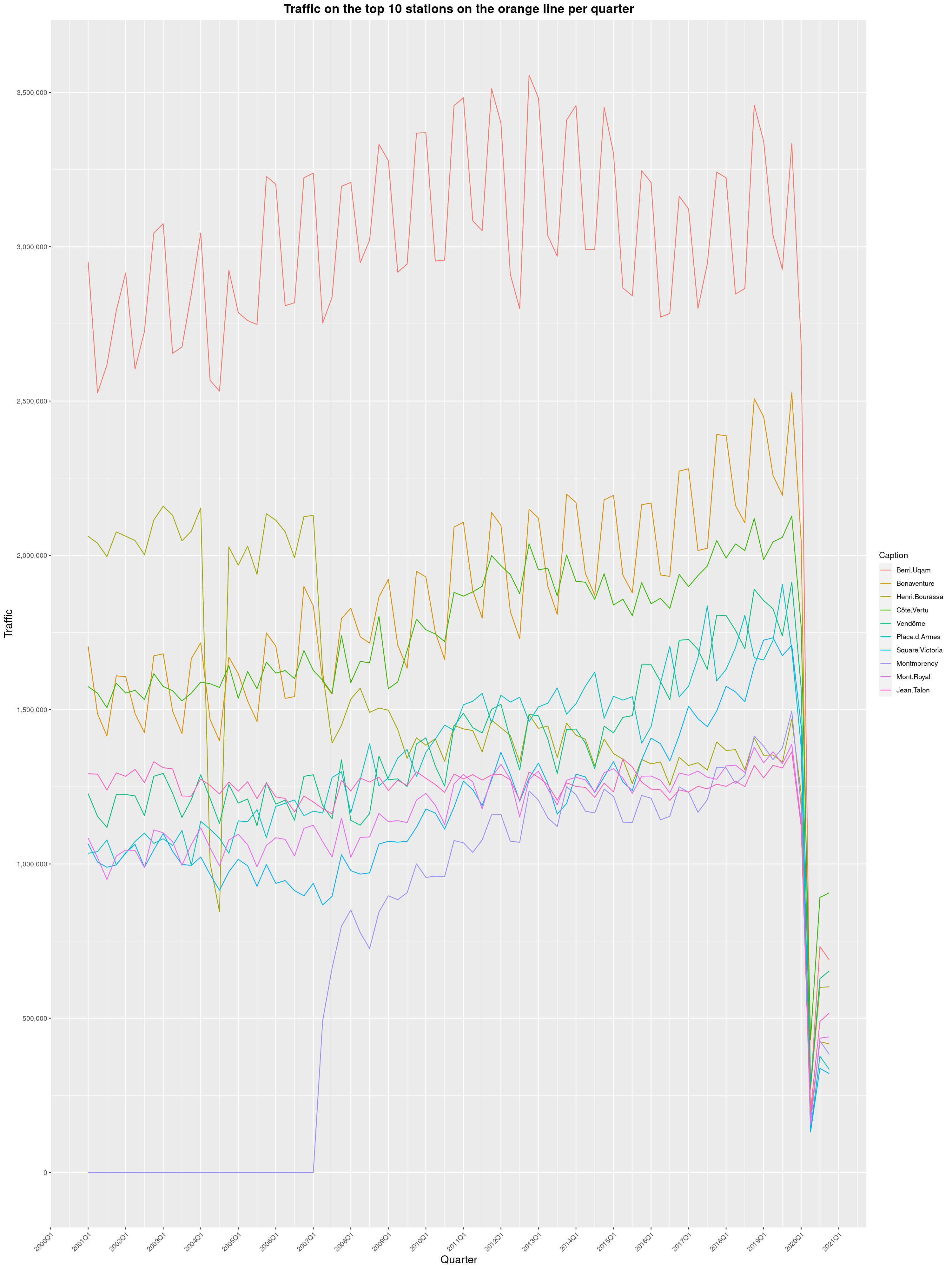{kind=link}
{kind=link}
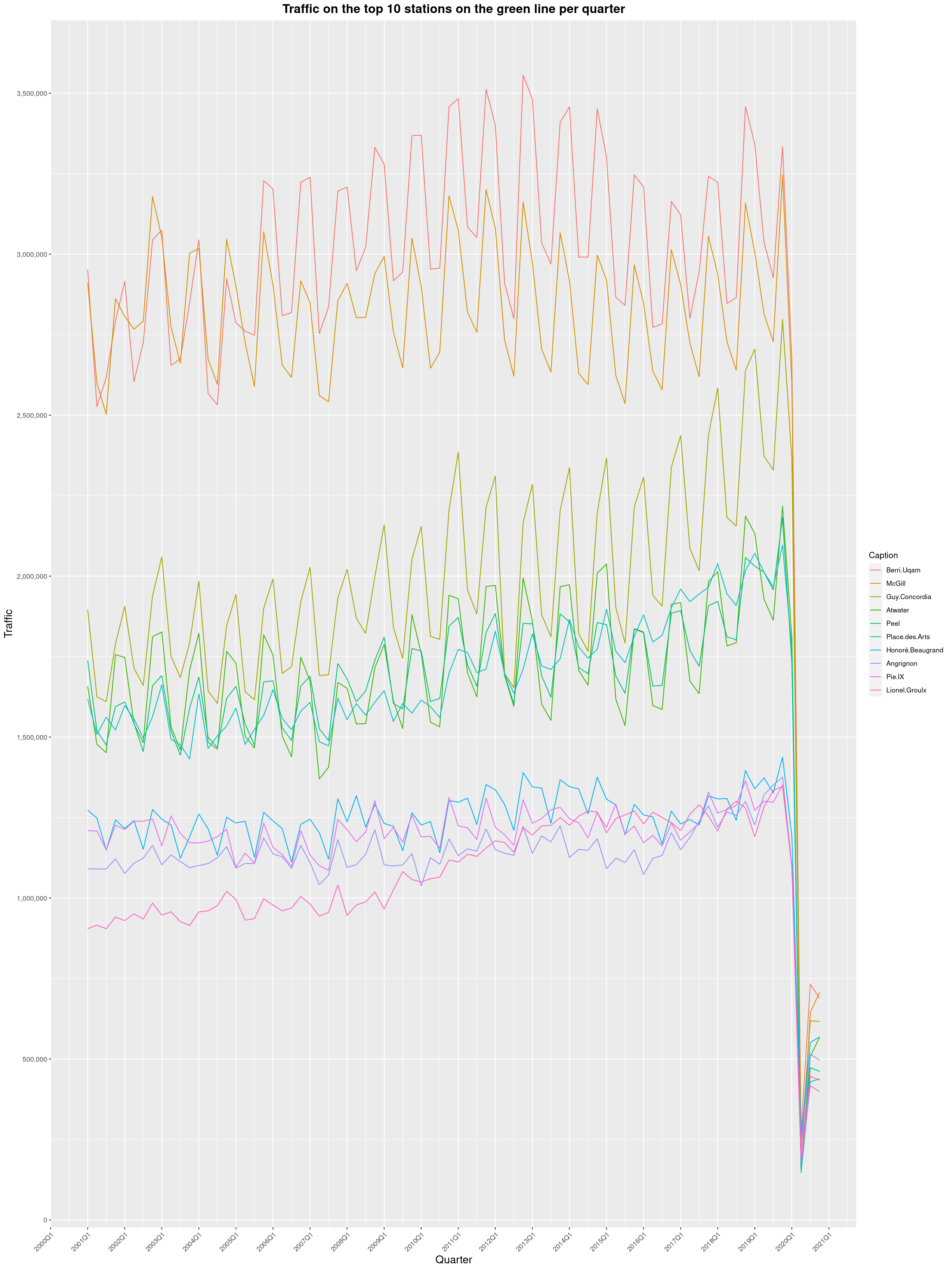{kind=link}
{kind=link}
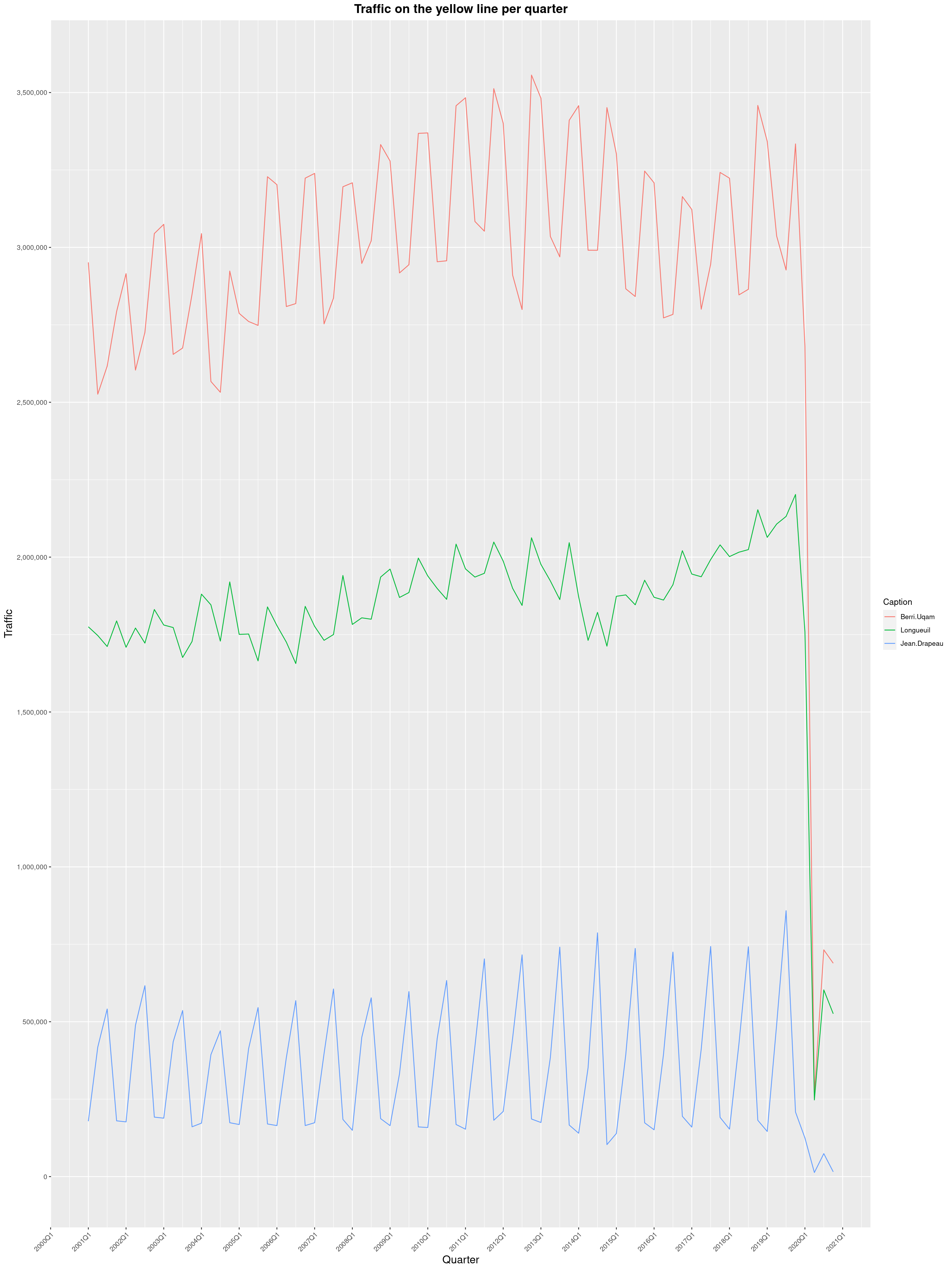{kind=link}
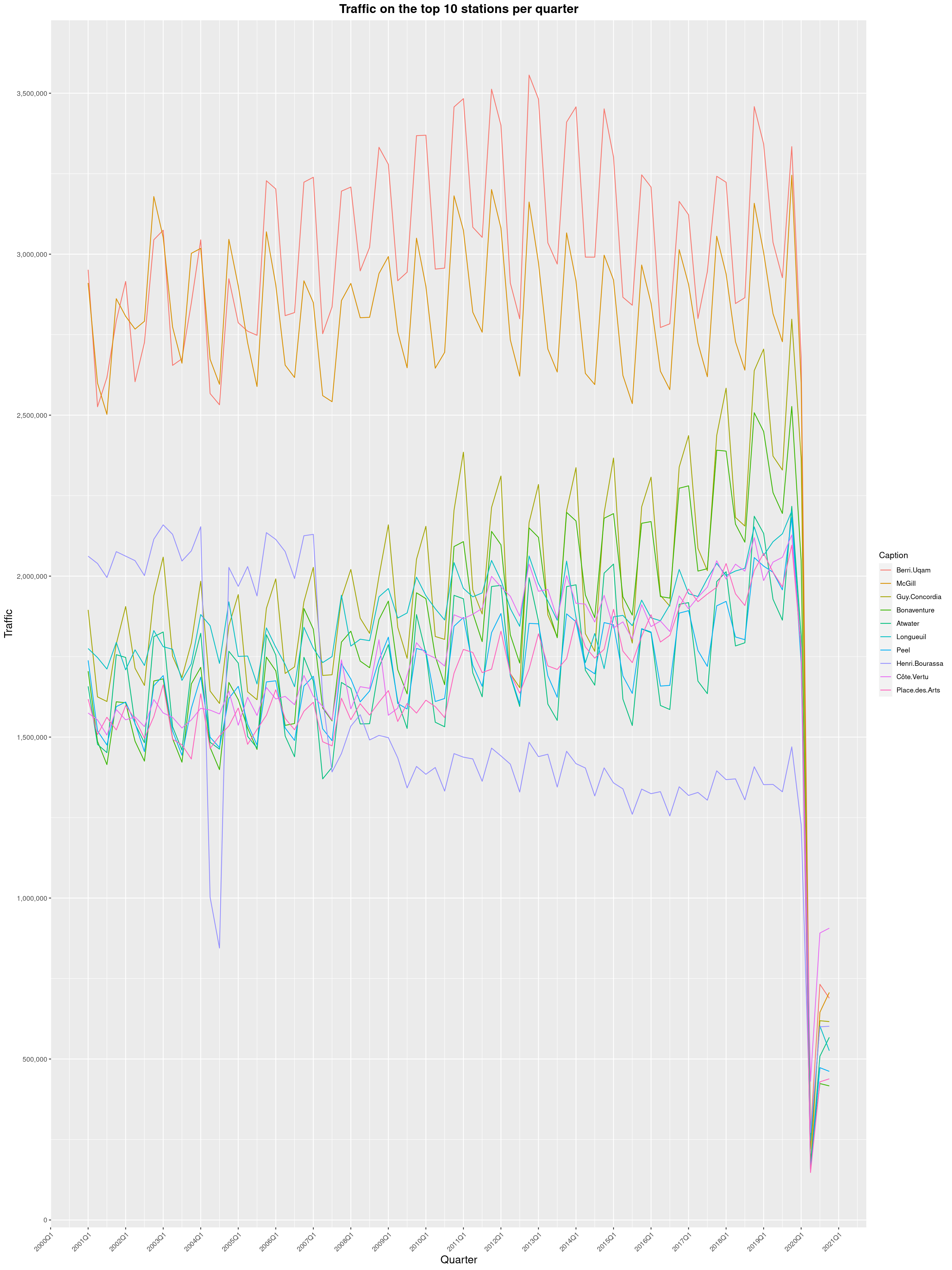{kind=link}
{kind=link}
{kind=link}
{kind=link}